머신러닝 기술스택 점검 겸, 논문과 병행하여 진행하고 있는 프로젝트에서 사용하기 위한 TensorFlow.js를 공부하기 위한 카테고리 및 포스팅이다.
http://www.yes24.com/Product/Goods/108441844
구글 브레인팀에게 배우는 딥러닝 with TensorFlow.js - YES24
브라우저에서 딥러닝 모델을 빌드하고 실행하는 TensorFlow.js딥러닝 기초부터 구글 브레인 팀의 노하우까지!딥러닝은 컴퓨터 비전, 이미지 처리, 자연어 처리 등 다양한 분야에 변화를 불러왔다.
www.yes24.com
책은 다음 책을 사용하고 있고, 그동안 배워온것들을 정리하면서 사용하자는 마인드로 이 책을 완독하고자 한다.
하루에 최대한 나갈 수 있는만큼 빠르게 나가도록 한다. 또한, 책을 읽으면서 개념들을 정리하고자 한다.
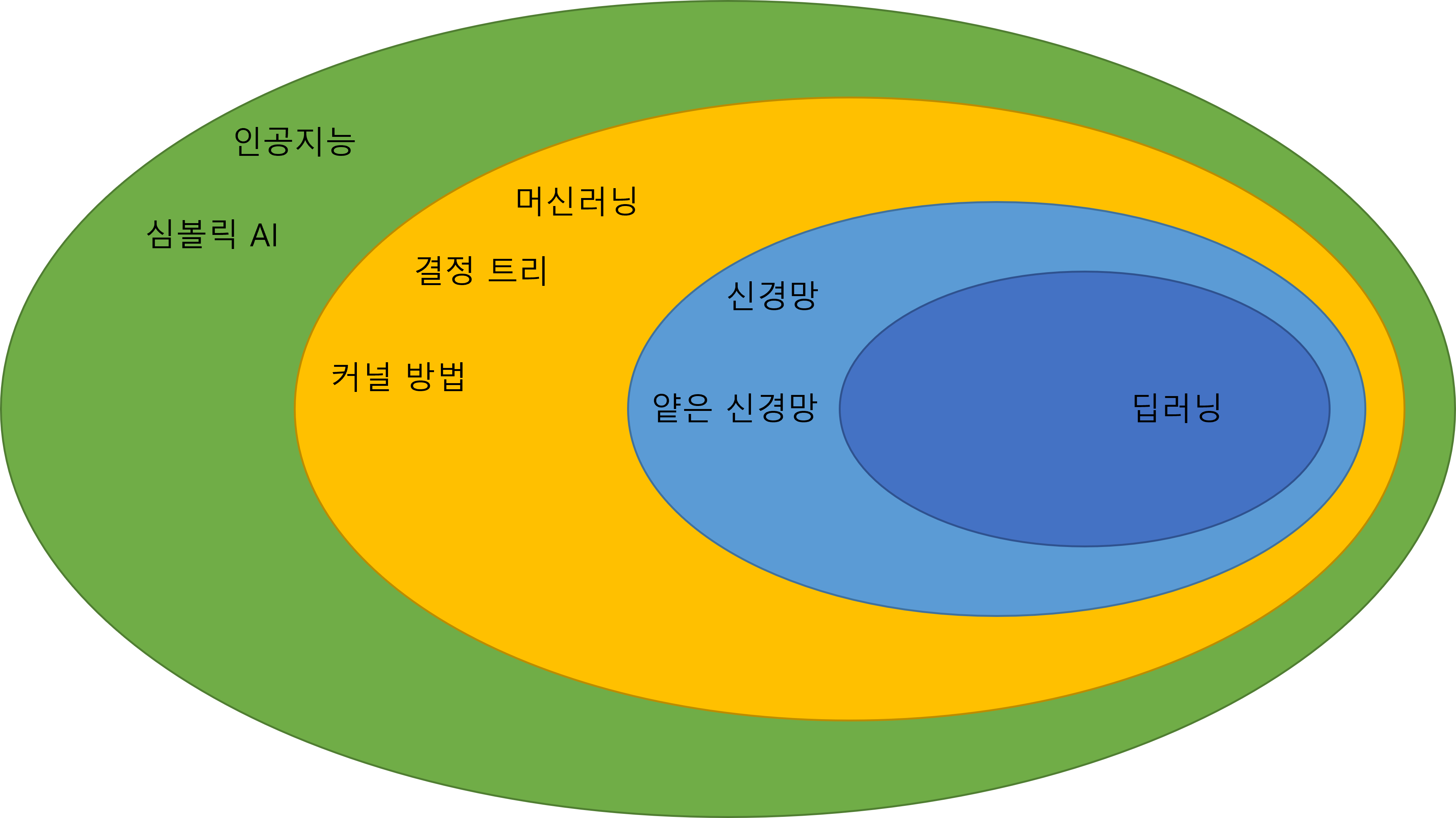
심볼릭 AI (Symbolic AI): 경우의 수를 하드코딩한 인공지능을 의미한다.

전통적인 프로그래밍은 규칙을 프로그래머가 규정하고, 해당 규칙을 기반으로 데이터를 정답으로 분류한다.
머신러닝은 레이블이라고 불리는 정답값과 데이터를 이용하여 규칙을 찾는 방식이라고 할 수 있다.

머신 러닝의 단계는 크게 훈련 단계(Training), 추론 단계(Inference) 두 개의 중요한 단계가 있다.
데이터와 레이블 한쌍을 example이라 하며, 여러 example들을 모아 training data라 한다. (나는 뭔가 training set이 입에 맞는다)
이 Data와 label을 통해서 어떤 규칙(Rule)을 훈련 과정을 통해 발견한다. 규칙을 수립하기 위해서 모델(model)을 사용하며, 가설 공간(hypothesis space)를 형성한다.
훈련 과정에서는 모델의 출력이 정답에 가까워 지도록 수정하는 과정을 거친다.
위 그림처럼 데이터와 정답이 있고, 모델 출력의 에러를 점진적으로 줄여나가는 방법을 지도학습(supervised learning)이라 한다.
비지도학습(unsupervised learning)
레이블되지 않은 데이터를 사용.
예시로는 clustering(군집, 클러스터링), anomaly detection(이상치 탐지)
신경망과 딥러닝
인공 신경망(artificail neural network)
인공 신경망은 층(layer)이라 부르는 분리 가능한 여러 단계에서 데이터를 처리
층의 메모리는 가중치(weight)에 저장됨
이 장에서 용어정리는 이정도이고, 나머지는 기본적으로 알고있던 내용들이 있었다.
책은 확실히 정리가 잘 되어있다.
TensorFlow.js를 사용하는것에 대한 장점도 있으니, 책을 한번 읽어보길 바란다.