Requirement
python 3.7.16
tensorflow==2.3.0
CUDA 10.1
cuDNN 8.0.5 for CUDA 10.1
tensorflow까지만 version을 지정해주었고, 나머지는 딱히 버전을 지정하지 않았습니다.
opencv-python==4.7.0.72
권장 : opencv-python==4.1.2.30
easydict==1.10
pillow==9.4.0
기본적인 YOLO 수행 방법
- https://github.com/hunglc007/tensorflow-yolov4-tflite 으로 가서 git clone을 통해 파일들을 다운로드 한다.
- git clone 했을 경우 tensorflow-yolov4-tflite 라는 폴더가 생성된다.
- weight에서 YOLO v4 weight를 다운로드 받는다.
- tensorflow-yolov4-tflite/data 폴더에 다운로드 받은 weight를 복사(이동)한다.
- 아래 명령어를 이용하여 darknet weight를 tensorflow weight로 바꾼다. 아래 명령어를 수행하면 tensorflow-yolov4-tflite/checkpoints/yolov4-416에 saved_model.pb파일이 생성된다.
python save_model.py --weights ./data/yolov4.weights --output ./checkpoints/yolov4-416 --input_size 416 --model yolov4- 이제 tensorflow로 YOLO를 수행할 준비가 끝났다!
또는 python detect.py 로 demo를 수행해 볼 수 있다.python detect.py --weights ./checkpoints/yolov4-416 --size 416 --model yolov4 --image ./data/kite.jpg
※주의사항※
detect.py 수행 시,
cv2.error: OpenCV(4.7.0) :-1: error: (-5:Bad argument) in function 'rectangle'다음과 같은 에러가 발생하는 경우가 있다.
해결 방안은 총 2가지가 있다.
1. opencv 버전을 낮춘다.
- 버전 어디서부터 어디까지 작동되는지 범위는 구체적으로 알수없으나, opencv==4.1.2.30 인 경우에는 문제없이 잘 작동되는것을 볼 수 있다. 코드를 수정하고 싶지 않다면 opencv를 다운그레이드하는 방법도 있다.
2. utils.py를 수정한다.
명확히 설명할 수 없지만, opencv의 버전이 올라가면서 int값을 parameter로 전달하도록 규칙이 바뀐것 같다.
다음은 오류가 발생하는 153, 159번째 줄을 포함하는 139~163줄 까지의 utils.py 코드이다. utils.py는 core 폴더 내부에 위치한다.for i in range(num_boxes[0]): if int(out_classes[0][i]) < 0 or int(out_classes[0][i]) > num_classes: continue coor = out_boxes[0][i] coor[0] = int(coor[0] * image_h) coor[2] = int(coor[2] * image_h) coor[1] = int(coor[1] * image_w) coor[3] = int(coor[3] * image_w) fontScale = 0.5 score = out_scores[0][i] class_ind = int(out_classes[0][i]) bbox_color = colors[class_ind] bbox_thick = int(0.6 * (image_h + image_w) / 600) c1, c2 = (coor[1], coor[0]), (coor[3], coor[2]) cv2.rectangle(image, c1, c2, bbox_color, bbox_thick) if show_label: bbox_mess = '%s: %.2f' % (classes[class_ind], score) t_size = cv2.getTextSize(bbox_mess, 0, fontScale, thickness=bbox_thick // 2)[0] c3 = (c1[0] + t_size[0], c1[1] - t_size[1] - 3) cv2.rectangle(image, c1, (np.float32(c3[0]), np.float32(c3[1])), bbox_color, -1) cv2.putText(image, bbox_mess, (c1[0], np.float32(c1[1] - 2)), cv2.FONT_HERSHEY_SIMPLEX, fontScale, (0, 0, 0), bbox_thick // 2, lineType=cv2.LINE_AA) return image이 코드에서 cv2.rectangle을 사용하는데 있어서 파라미터는 다음과 같다.
(img, pt1, pt2, color, thickness, lineType, shift)
여기에서 pt1과 pt2에서 int값을 요구하고 있다. 따라서 int값을 적절하게 넣어주어야 코드가 작동한다.
참 웃기게도 coor에 대해서 모두 int로 변경하였으나, c1, c2로 묶는 과정에서 int->float로 변환이 일어난다 (왜그런지는 모르겠다...) 따라서 153줄을c1, c2 = (int(coor[1]), int(coor[0])), (int(coor[3]), int(coor[2]))으로 수정해주고, 159줄을
cv2.rectangle(image, c1, (int(c3[0]), int(c3[1])), bbox_color, -1)로 수정해주면 detect.py가 잘 수행된다.
이렇게 기본적인 YOLO 수행 준비를 끝마쳤으면, 이제 하고자 하는것을 해볼 차례이다.
Model load test
제공하는 파일인 detect.py에서는 model을 다음과 같이 load하고 있다.
saved_model_loaded = tf.saved_model.load(FLAGS.weights, tags=[tag_constants.SERVING])
infer = saved_model_loaded.signatures['serving_default']FLAGS.weights는 weight 위치를 의미한다. 다음과 같이 model을 load하는 경우에는 layer 단위로 분석할 수 없다. 자세한 내용은 다음을 참고한다.
또한 위와 같이 model을 load하여 추론(inference)하는 경우에는 최종 결과를 dictionary형태로 제공한다. 따라서 원래 코드에서는
for key, value in pred_bbox.items():
boxes = value[:, :, 0:4]
pred_conf = value[:, :, 4:]다음과 같이 인식한 객체를 감싸는 박스와, 해당 객체의 label에 대한 확률을 나눈다.
따라서 Layer by layer (LBL)로 뜯어보기 위해서, 다음과 같이 model을 load한다.
infer = tf.keras.models.load_model('./checkpoints/yolov4-416')먼저 LBL로 들어가기 앞서, tf.keras.models.load_model로 load한 경우에도 추론이 잘 되는지 확인하기 위헤 다음과 같이 코드를 수정하여 수행하였다. 위와같이 model을 load하고 infer(Input) 로 추론할 경우에는 최종 결과를
tensorflow.python.framework.ops.EagerTensor 로 제공하기 때문에, 다음과 같이 코드를 수정해야 한다.
boxes = pred_bbox[:, :, 0:4]
pred_conf = pred_bbox[:, :, 4:]다행히 다음과 같이 코드를 수정했을 경우에는, 좋은 결과를 얻을 수 있었다.
Layer wise execution
그러면 이제 tf.keras.models를 사용해서 각 모델을 layer 단위로 분해해보도록 하겠다.
infer.layers
# type(infer.layers) : <class 'list'>를 통해서, infer (현재 tf.keras.models.load_model을 통해 load한 yolo 모델)를 구성하고 있는 모든 layer를 list로 받을 수 있다.
result = INPUT
for layer in infer.layers:
result = layer(result)다음과 같은 방식으로, 각 layer를 개별적으로 call할 수 있다.
그러나 YOLO의 경우에는 레이어들이 Sequencial하게 있는것 뿐만 아니라, Residual block이 다수 존재하고, input을 나누는 split layer, 두 layer를 연결하는 concat layer등... 위 방식만으로는 해결하지 못하는 경우가 다수 있다.
이를 해결하기 위해 각 layer의 이름을 key로 하고, layer의 output을 value로 하는 dictionary를 생성하여 이를 해결하고자 했다. output을 저장하는 dictionary는 layer by layer 추론을 진행하며 update 한다.
또한 각 layer에서 다음에 어떤 layer가 올지 알 수 없지만, predecessor layer에 대한 정보는 알 수 있기때문에, 역시 layer의 이름을 key로 하고, layer의 predecessor name을 갖는 list를 value로 하는 dictionary도 생성한다. 방법은 다음과 같다.
predecessorInfo = {}
OutputSaver={}
for layer in infer.layers:
# initialize OutputSaver dict
OutputSaver[layer.name] = 0
# initialize predecessor information
int_node = layer._inbound_nodes[0]
predecessorInfo[layer.name]=[]
try:
# if layer has multi ancestor
for predecessor_layers in int_node.inbound_layers:
predecessorInfo[layer.name].append(predecessor_layers.name)
except:
# if layer has one ancestor
predecessorInfo[layer.name].append(int_node.inbound_layers.name)하지만 위 두 작업으로는 충분하지 않다. split layer가 문제를 일으키기 때문이다.
split layer는 layer.name을 호출할 경우 xxxx_split으로 이름이 나오기 때문에, 정규식을 통해 split layer를 따로 구분짓고, index를 부여하여 split되는 순서에 맞춰 분배하도록 한다. ( 혹시 여기서 split을 제대로 못하여 문제가 발생하는 것이 아닐까? )
re.compile('[a-z0-9_+.-]+split')그러면 이제 LBL로 수행 할 준비가 모두 끝났다!
이전 파이썬 수행 파일에서 한줄이면 끝났던 코드를, 다음과 같이 길게 LBL로 수행한다.
# before: pred_bbox = infer(input)
pred_bbox = input
for layer in infer.layers:
# second ~ last layer
tmppredecessorInfo = predecessorInfo[layer.name]
if tmppredecessorInfo:
# only one ancestor
if len(tmppredecessorInfo) == 1:
ancestor_name = tmppredecessorInfo[0]
pred_bbox = OutputSaver[ancestor_name]
# if ancestor is split layer
if p.match(ancestor_name):
try:
idx = splitCounter[ancestor_name]
except:
idx = splitCounter[ancestor_name] = 0
pred_bbox = pred_bbox[idx]
splitCounter[ancestor_name] += 1
if splitCounter[ancestor_name] == len(OutputSaver[ancestor_name]):
splitCounter[ancestor_name] = 0
pred_bbox = layer.call(pred_bbox)
OutputSaver[layer.name] = pred_bbox
# multi-ancestor
else:
pred_bbox=[OutputSaver[predecessor] for predecessor in tmppredecessorInfo]
# stack으로는 값을 제데로 전달 불가능 - 2023.02.19
# pred_bbox = tf.stack(pred_bbox, axis=0)
pred_bbox = layer.call(pred_bbox)
OutputSaver[layer.name] = pred_bbox
else:
# only the first layer
pred_bbox = layer.call(pred_bbox)
OutputSaver[layer.name] = pred_bbox
boxes = pred_bbox[:, :, 0:4]
pred_conf = pred_bbox[:, :, 4:]multi ancestor인 경우에 tf.stack을 이용해 vertical하게도, horizontal하게도 쌓아서 call하는 경우에는 올바르게 동작하지 않았다. 아마 tf.stack을 불러 하나의 tensor로 만들어 버리기 때문이라 생각한다. 여러번 시도했으나 layer call에 성공하지 못했고, list로 두가지의 tensor를 입력으로 주는 경우에만 성공했다.
현재 값은 안정적으로 통과하지만, 마지막 결과에서 bounding box를 올바르게 치지 못하는 상황을 발견했다.
따라서, LBL의 출력 값과 model을 수행하는 경우의 출력값들을 비교해보고자 했다.
for layer in infer.layers:
if PRINTLAYERINFO:
print(f'\n{layer.name}')
imm_layer_model = tf.keras.Model(inputs=infer.input, outputs=layer.output)
imm_output = imm_layer_model(batch_data)
Immoutput[layer.name]=imm_output다음과 같이 코드를 구성하여, 각 레이어의 실제 output 값과 LBL로 수행할 경우의 레이어의 output 값을 비교해 보기로 하였다.
새탭으로 이미지를 열면 크게 볼 수 있다.

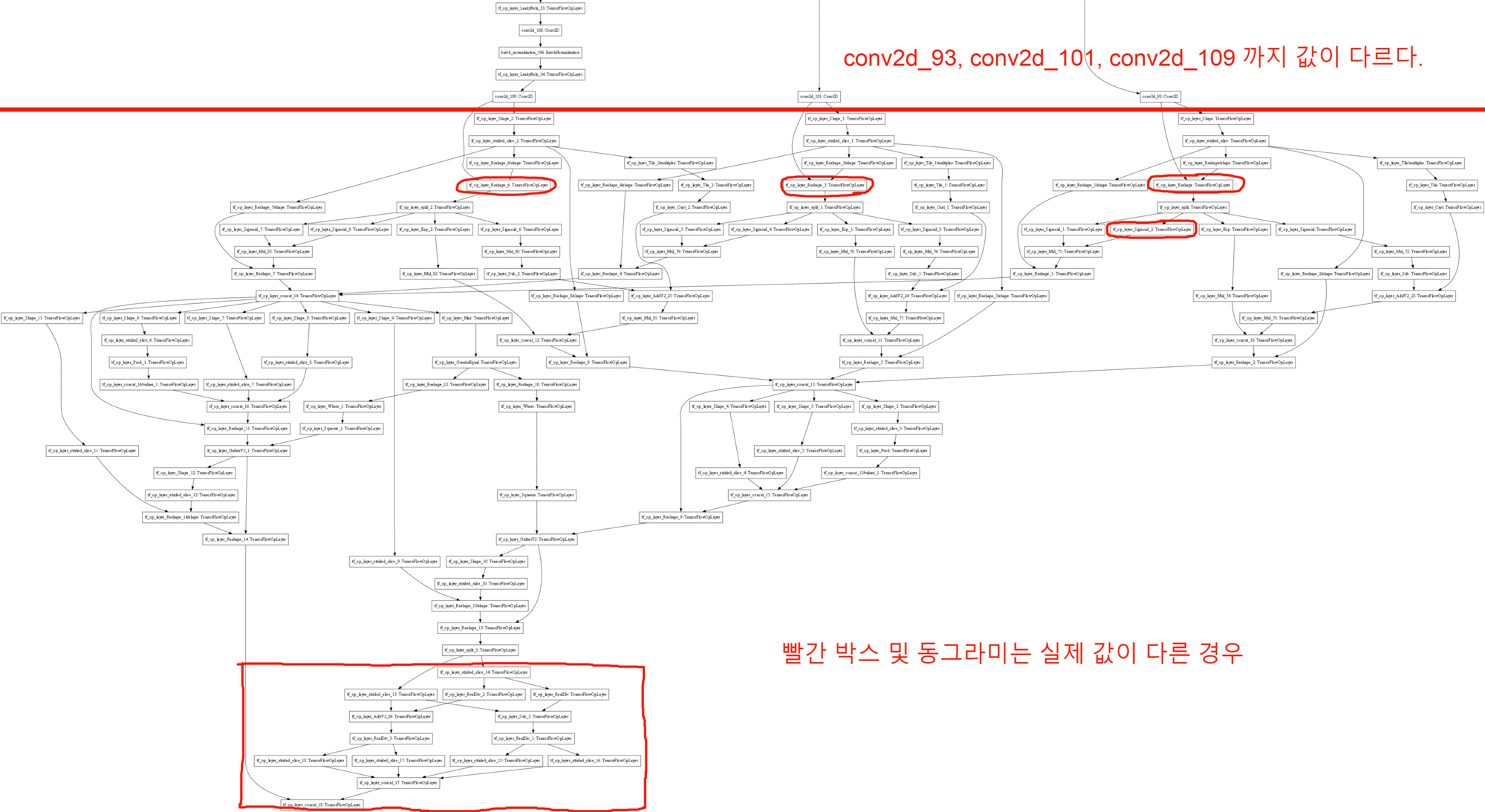
값 비교는 numpy.allclose 를 사용했고, 1e-06오차 이내로 차이가 나면 같은 값으로 설정한 경우에 다음과 같은 결과가 나왔다.
혹시나 해서 conv2d_73의 weight도 확인을 해봤는데, weight는 동일했다..
입력도 동일하고 weight도 동일한데 왜 output에서 차이가 나는지를 모르겠다
이번에는 오차 범위를 줄여서 검사해보았다.
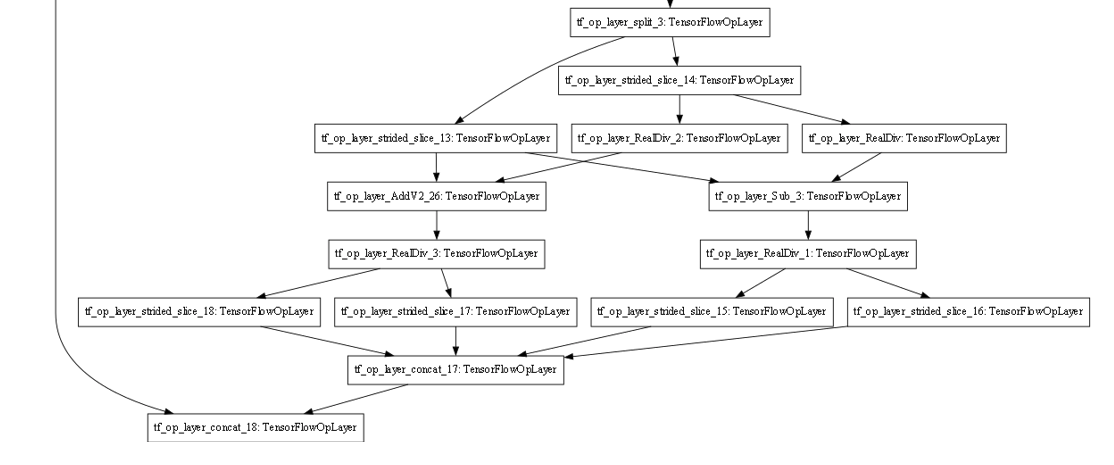
1e-04정도의 오차 범위를 가질 경우, tf_op_layer_split_3의 결과까지 동일하다고 판단하였고, 그 이후에서 부터 문제가 발생했다.
따라서 split의 값을 주는 순서가 올바르지 않다고 판단하여 한번 강제로 순서를 바꿔보았다.
그래도..여전히 strided_slice_14, 13을 수행하는데 문제가 있었다..
여기서 tf_op_layer_split_3의 output 값의 전달이 잘못 되고있다고 판단하여,
기존에 split의 경우 index 0부터 시작했지만, 이 경우에는 거꾸로 1->0 순서로 진행되도록 바꿔보았다.
그 결과는...

드디어!!!
제대로 결과가 나왔다.
이제 길고 길었던 LBL yolo 수행이 막을 내렸다.
'끄적끄적' 카테고리의 다른 글
| TensorFlow에서 재밌는 점 (in Yolov4) (0) | 2023.04.19 |
|---|---|
| TFLite visualizing (0) | 2023.04.06 |
| layer merge하는 경우 수행 시간에 대한 고찰 (0) | 2023.02.17 |
| TensorFlow관련 주저리... (0) | 2023.02.06 |
| Non-Sequential Model 묶기 - Part 2 (2) | 2023.02.03 |



