논문 작성에 있어서, 비교대상이 Yolo같은 고이장히 범용적으로 사용되는, 그리고 유명한 모델을 사용하면 좋을것 같아서, Yolo를 분석해 보았다.
내가 하고자 하는것은 병렬처리이기 때문에, 이 Yolo 모델을 적당히 나눌곳이 필요했다.
그러나 생각보다 모델 내부 구조가 복잡하여, 적절히 나눠야 할것같았고, Yolo v4의 후반부는 Yolo v3로 이뤄졌고, Yolo v3파트를 어느정도 병렬화가 가능하다는 판단이 들었다.
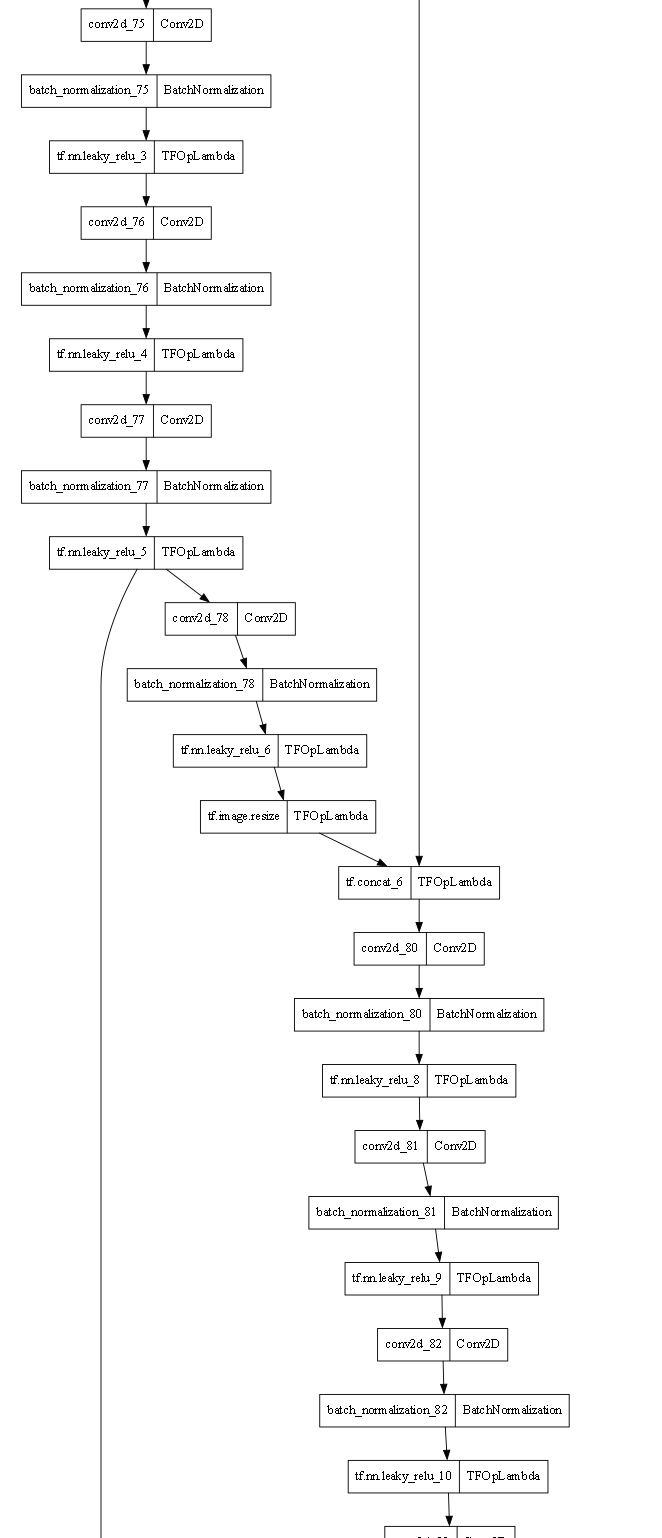
plot_model로 모델 구조를 출력해보았으나, 너무 크기가 커 다 올라가지는 않지만, 후반부분의 어느정도는 대부부느 Sequencial하게 이루어졌기 때문에, 충분히 가능성이 있다고 생각되었다.
Yolo의 다운로드 및 기초작업은 https://webnautes.tistory.com/1417를 참고했다.
YOLO v4 욜로 v4 실행시키는 방법
다음 깃허브에 있는 욜로 YOLO V4를 실행하는 방법을 소개합니다. hunglc007 / tensorflow-yolov4-tflite ( https://github.com/hunglc007/tensorflow-yolov4-tflite ) 관련 포스트 Ubuntu에서 darknet을 사용하여 Yolo v4 커스텀 학
webnautes.tistory.com
weight의 경우에는 대부분의 링크가 파손되어있어 구하기 쉽지 않았는데, 운이좋게 구했다.
https://drive.google.com/file/d/1WPrkrt9HmdLvDSyo4mO4mMXnMerzMil_/view?usp=share_link
yolov4.weights
drive.google.com
내가 가지고 있는 weight를 마음대로 공유해도 되는지는...잘 모르겠다. 만약에 문제가 생길경우 공유는 중단겠다.
굳이 방식에 대해서 여기서 설명할 필요는 없을것 같고, 위 블로그를 참조하면 되겠다.
그러나 현재 tensorflow==2.10.0과 CUDA==11 환경에서 video 인식이 잘 되지 않아서, 대부분이 Yolo v4에서 권장하는 tensorflow==2.3.0으로 내리고, tensorflow에 맞는 CUDA==10으로 맞춰주기로 하였다.
다음은 CUDA를 변경하는 방법 이고 (https://tw0226.tistory.com/79)
[CUDA] 윈도우 환경에서 CUDA 버전 변경
어떤 github의 딥러닝 코드는 tensorflow 1.14 버전을 썼는데, 1.14 버전은 CUDA 11버전이 호환되지 않아서 1. python 버전 변경 2. tensorflow 재설치 3. CUDA 버전 번경 (11 -> 10) 의 절차가 필요하였다. 나의 상황
tw0226.tistory.com
버전 내리는 법은 그냥 버전 맞춰서 다시
pip install tensorflow==2.3.0해주면 알아서 잘 downgrade 된다.
cuDNN https://developer.nvidia.com/rdp/cudnn-archive넣어주는거 잊지말자.
추가적으로 말하자면, yolo v4 다크넷 가중치 변환은 CUDA 및 cuDNN, tensorflow 설치가 완료된 이후에 하도록 하자!
미리 가중치를 이전에 사용하던 CUDA나 cuDNN, tensorflow를 사용하여 변환 후 버전을 내리고, CUDA를 변경할 경우 오류 메시지를 출력하며 동작하지 않는다.
일단은 잘 작동하는것을 확인했다.
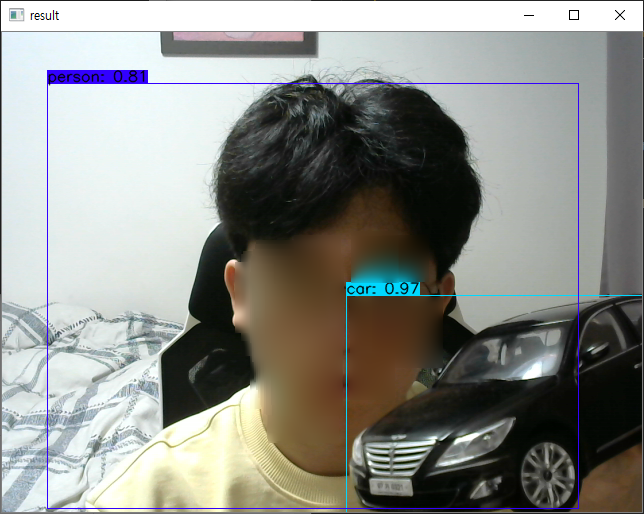
여기서 내 문제는 이거였다.
과연 모델을 tf.keras.models.load_model로 하여도 비슷한 결과를 가지고 올것인가?
따라서 나는 수행해보고자 하였다.
tf.keras.models.load_model로 수행하는 경우에는 몇가지 코드를 변경해주어야한다.
# origin
saved_model_loaded = tf.saved_model.load(MODEL_PATH, tags=[tag_constants.SERVING])
infer = saved_model_loaded.signatures['serving_default']
#tf.keras.models.load_model
infer = tf.keras.models.load_model('./checkpoints/yolov4-416')먼저 tf.saved_model 이 아니기 때문에, 다음과 같이 model을 load한다.
# origin
for key, value in pred_bbox.items():
boxes = value[:, :, 0:4]
pred_conf = value[:, :, 4:]
#tf.keras.models.load_model
batch_data= tf.constant(images_data)
pred_bbox = infer(batch_data)그리고 이미지 추론 이후, 추론 결과를 다음과 같이 수정한다.
tf.keras.models.load_model로 수정할 경우에는 레이어의 정보를 확인하기 편했다.
그러나 큰 문제점으로는 fps가 떨어지는 문제가 있었다.
| tf.saved_model.load | tf.keras.models.load_model | |
| Avg time | 191.21648057510978 | 389.11195570422757 |
| Max time | 491.8937683105469 | 1561.2826347351074 |
| Min time | 185.380220413208 | 353.8167476654053 |
| fps | 5.23 | 2.56 |
fps가 2배 가까이 차이가 나는 문제가 있었다.
추론 시간을 단축하기 위해서는, tf.saved_model에서도 레이어를 분리하여 수행하는 방법에 대해 알아봐야 한다고 생각한다.
부끄럽게도 제대로 알지도 못하고 글을 썼다.
'끄적끄적' 카테고리의 다른 글
| Non-Sequential Model 묶기 - Part 2 (2) | 2023.02.03 |
|---|---|
| Non-Sequential Model 묶기 (0) | 2023.02.02 |
| (TensorFlow) 첫번째 추론 시간, First inference time (0) | 2023.01.30 |
| batch predict, 개별 predict, 개별 call, layer by layer (0) | 2023.01.27 |
| predict, call, batch_size (0) | 2023.01.26 |


