Yolo를 성공적으로 설치하고, tf.keras.models로 변환 후 모든 레이어의 연결상태를 확인한것은 아주 좋은 일이었다.
그러나 새로 직면한 문제는, 이 복잡한 모델 구조들을 얼마나, 어떻게 적절하게 일련의 번호로 순서를 매길것이냐? 라는 문제를 직면했다.
가장 먼저 생각났던 아이디어는, 갈래가 생기는 경우에는 하나로 묶어버리자! 라는 생각이었다.
노가다성이 조금 짙었지만, 나는 이전에 추출한 yolo 모델 구조 이미지를 통해서, 위 아이디어로 수행할 경우 얼마나 분할이 되는지 알아보고자 하였다.
하지만 위 아이디어대로 묶어버린다면, 너무 작은 덩어리와 큰 덩어리들의 집합으로 묶여져버린다.
두번째로 생각한 아이디어는 index번호를 이용해보자는 생각이었다.
나는 우선 다음과 같은 모델을 제작하여, 테스트 해보기로 하였다.
가장 기본이 되는 MNIST dataset을 사용하기로 하였다.
내가 원래 사용하던 환경에서는 이상하게
Node: 'model/conv2d/Relu'
DNN library is not found.
[[{{node model/conv2d/Relu}}]] [Op:__inference_train_function_1118]와 같은 오류가 나서, yolo v4(어차피 얘를 병렬화 하려고 한것이기 때문에) 환경과 동일하게 맞췄다.
yolo v4가 tensorflow==2.3.0에서 동작해서, CUDA 10.1 환경변수를 11.1보다 올려뒀던것을 까먹었다.
환경변수 우선순위 변경해 주니 이런 오류는 나지 않았다.
다음번에 이런 오류를 만나면 CUDA 환경변수 우선순위가 잘 맞는지 먼저 확인하자.
GPU Type: NVIDIA RTX 3070Ti
CUDA Version: 10.1
Operating System + Version: Windows 10
Python Version: 3.7.16
TensorFlow Version: 2.3.0
# Type 1
from tensorflow.keras import datasets, layers, models
from tensorflow.keras.utils import plot_model
input = layers.Input(shape=(28,28,1))
conv1 = layers.Conv2D(32,(3,3),activation='relu')(input)
pool1 = layers.MaxPool2D((2,2))(conv1)
conv2 = layers.Conv2D(64, (3, 3), activation='relu')(pool1)
pool2 = layers.MaxPooling2D((2, 2))(conv2)
conv3 = layers.Conv2D(64, (3, 3), activation='relu')(pool2)
pool3 = layers.MaxPooling2D((2, 2))(conv3)
flat1 = layers.Flatten()(pool3)
dense1 = layers.Dense(32, activation='relu')(flat1)
dense11 = layers.Dense(64,activation='relu')(flat1)
dense12 = layers.Dense(32,activation='relu')(dense11)
merge = layers.concatenate([dense1, dense12])
output = layers.Dense(10,activation='softmax')(merge)
model = models.Model(inputs=input, outputs=output)인덱스 번호를 확실하게 확인하기 전에, 나눠졌다가 합쳐지는 과정에서 model 생성 순서가 다르더라도 동일한 인덱스를 부여하는지 확인을 해야 했기 때문에, 다음과 같이 모델을 생성하고 model.layers에 저장된 layer의 순서를 출력해 보았다.
# Type 2
input = layers.Input(shape=(28,28,1))
conv1 = layers.Conv2D(32,(3,3),activation='relu')(input)
pool1 = layers.MaxPool2D((2,2))(conv1)
conv2 = layers.Conv2D(64, (3, 3), activation='relu')(pool1)
pool2 = layers.MaxPooling2D((2, 2))(conv2)
conv3 = layers.Conv2D(64, (3, 3), activation='relu')(pool2)
pool3 = layers.MaxPooling2D((2, 2))(conv3)
flat1 = layers.Flatten()(pool3)
# different Here
dense11 = layers.Dense(64,activation='relu')(flat1)
dense12 = layers.Dense(32,activation='relu')(dense11)
dense1 = layers.Dense(32, activation='relu')(flat1)
# different End
merge = layers.concatenate([dense1, dense12])
output = layers.Dense(10,activation='softmax')(merge)
model = models.Model(inputs=input, outputs=output)| Type 1 | Type 2 |
| input_1 conv2d max_pooling2d conv2d_1 max_pooling2d_1 conv2d_2 max_pooling2d_2 flatten dense_1 dense dense_2 concatenate dense_3 |
input_1 conv2d max_pooling2d conv2d_1 max_pooling2d_1 conv2d_2 max_pooling2d_2 flatten dense dense_2 dense_1 concatenate dense_3 |
큰 차이는 없어보이지만, dense layer에서 순서가 조금 변경이 되었기에, plot_model로 차이를 확실하게 확인해보았다.
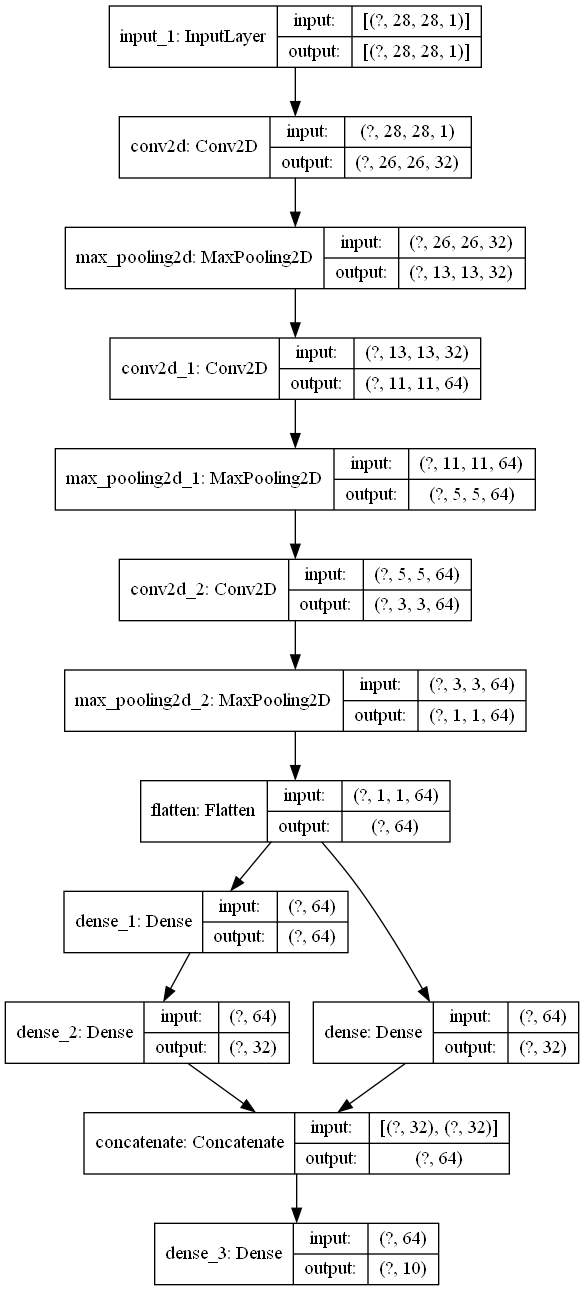
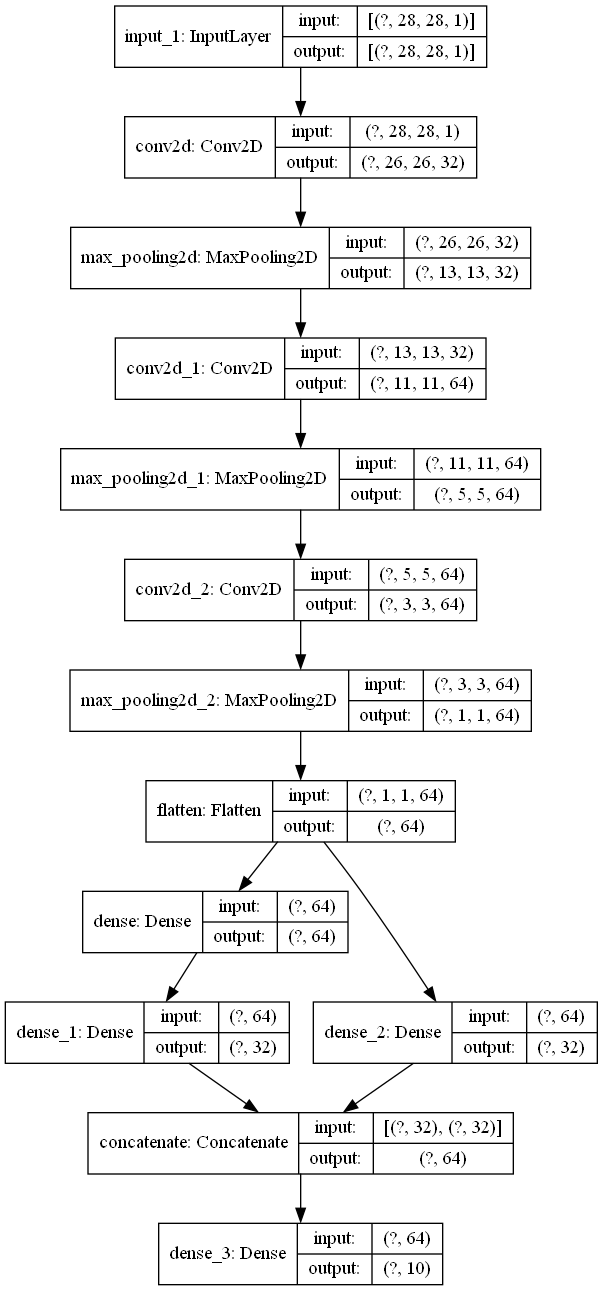
다행히도 layer의 이름에 영향이 갔고, model.layers에 저장된 순서에는 영향이 있지는 않았다.
나는 model의 코드보다는 model을 load하여 사용하는것에 목적을 두었기 때문에, train후 model을 따로 저장하였다.
model = tf.keras.models.load_model('saved_model/merged_model')
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
loss, acc = model.evaluate(test_images, test_labels, verbose=2)
# result: 313/313 - 1s - loss: 0.0492 - accuracy: 0.9851load가 잘 되며, 결과도 잘 나오는것을 볼 수 있다.
이제 내가 궁금한것은, 과연 이것을 layer by layer로 수행해도 잘 작동할 것인가?
이제 필요한것은, 각 layer들이 어떤 layer로 이어져있는지, 해당 관계를 알아야 한다.
따라서 다음과 같은 dictionary들을 생성했다.
predecessorInfo = {}
OutputSaver={}predecessor_Info는 key: current_layer.name, value: [predecessor_layer.name, ... ] 로 구성되어 있다.
predecessor_layer.name은 current_layer가 data를 전달받는 layer들의 array 정보를 포함하고 있다.
예를들어. 위 사진으로 보았을때
predecessorInfo[dense_2] == [dense_1] 이며,
predecessorInfo[concatenate] == [dense_2, dense] 처럼 상위 레이어의 정보를 포함하고 있다.
OutputSaver는 key: layer.name, value : Output_tensor of layer 로 구성되어있다.
해당 layer의 immidiate output을 저장하고 있는 dictionary다.
.
.
.
오늘은 layer-by-layer로 진행하는데 있어서, 지속적으로
tensorflow.python.framework.errors_impl.InvalidArgumentError: cannot compute Conv2D as input #1(zero-based) was expected to be a double tensor but is a float tensor [Op:Conv2D]
에러가 발생했다.
이에대해 해결하기 위해서 layer.call하기 전에 input을 double로 변경하였으나, 그래도 동작하지 않았다.
내 영어실력의 하찮음을 다시금 깨달았다. 좀 여러 type으로 변경하면서 테스트를 해봤어야 했다.
나는 이 오류를 model은 double tensor를 원했으나, float가 들어왔다- 라고 해석하여 계속 type 변환을 double로 하였다..
사실 이거는 내가 double tensor를 넣어주었기 때문에 '내가' double tensor이길 바랬으나, 모델은 사실 float 였다! 로 해석할수 있겠다... 다신 이런 실수 하지 말자.
.astype(np.float32)를 data에 수행하는것만으로 해결이 되었다.
이에대한 해결법을 찾아야 할것같다.
'끄적끄적' 카테고리의 다른 글
| TensorFlow관련 주저리... (0) | 2023.02.06 |
|---|---|
| Non-Sequential Model 묶기 - Part 2 (2) | 2023.02.03 |
| Yolo 개척기 (2) | 2023.01.31 |
| (TensorFlow) 첫번째 추론 시간, First inference time (0) | 2023.01.30 |
| batch predict, 개별 predict, 개별 call, layer by layer (0) | 2023.01.27 |


