ABSTRACT
현재 많은 계산이 필요한 (computation-intensive) DNN을 자원이 제한된 (resource-constrained) 모바일 기기에 수행하는것에 대한 아이디어들은 모바일 client가 수행하고자하는 DNN 모델이 사전에 설치된 중앙 클라우드 서버에 DNN 쿼리를 요청한다. → decentralized cloud infrastructure에는 적합하지 않음
Decentralized cloud infrastructure에서는 clinent가 먼저 DNN model을 업로드 해야한다. → 업로드 하는 동안 심각한 딜레이 발생
IONN : partitioning-based DNN offloading technique for edge computing.
- client의 DNN 모델을 여러 개로 분할한다
- 분할한 모델을 하나씩 에지서버에 업로드한다
- 에지서버는 분할된 DNN 모델이 도착하면 순차적으로 DNN 모델을 만든다
- 전체 DNN 모델이 업로드 되기 전에 client에서 부분 DNN 수행을 할 수 있도록 한다
- 최적의 DNN 분할과 업로드 순서를 결정하기 위해서 IONN은 novel graph-based algorithm을 사용한다.
IONN은 현실적인 장비와 네트워크 상황에서 query performance에 대해 상당한 향상을 보였다.
INTRODUCTION
ABSTRACT에서 했던 이야기에 대해서 조금 더 자세하기 설명.
Deentralized cloud infrastructure에서는 client가 어떤 근처의 generic 서버에 ML query를 보낼 수 있기 때문에, 현실적으로 모든 nearby 서버에 DNN 모델을 사전에 install하는 것은 현실적이지 못하다. 또한 어떤 서버를 runtime때 사용할 지 알 수 없다. client가 이동중이라면 더더욱. 따라서 요청이 있을 때마다 client에서 DNN 모델을 업로드 하는것이 더욱 실용적이다. 그러나 요청이 있을때 마다 DNN 업로드를 하는것의 문제는 DNN 모델 업로드의 overhead가 크고, client는 에지 서버를 사용할 때까지 오래 기다려야 한다.
따라서 IONN을 제안. IONN은 client의 DNN 모델을 여러 개로 분할하고, 서버에 업로드 할 순서를 결정한다. client는 DNN 모델을 한번에 업로드하는 것이 아닌, 모델의 여러 분할을 하나씩 업로드한다. 에지 서버는 DNN 모델이 도착함에 따라서 순차적으로 DNN 모델을 만들고, 전체 모델이 업로드 되기 전부터 client에서 부분 DNN을 수행할 수 있도록 한다.
어떤 DNN query에 대해서 서버에 모델의 어떤 부분이 업로드 되기까지 시간이 걸린다면 client는 나머지 부분들에 대해 수행하며 병렬 수행 (collaborative execution, 본인은 병렬수행이라고 생각함)을 가능케 한다.
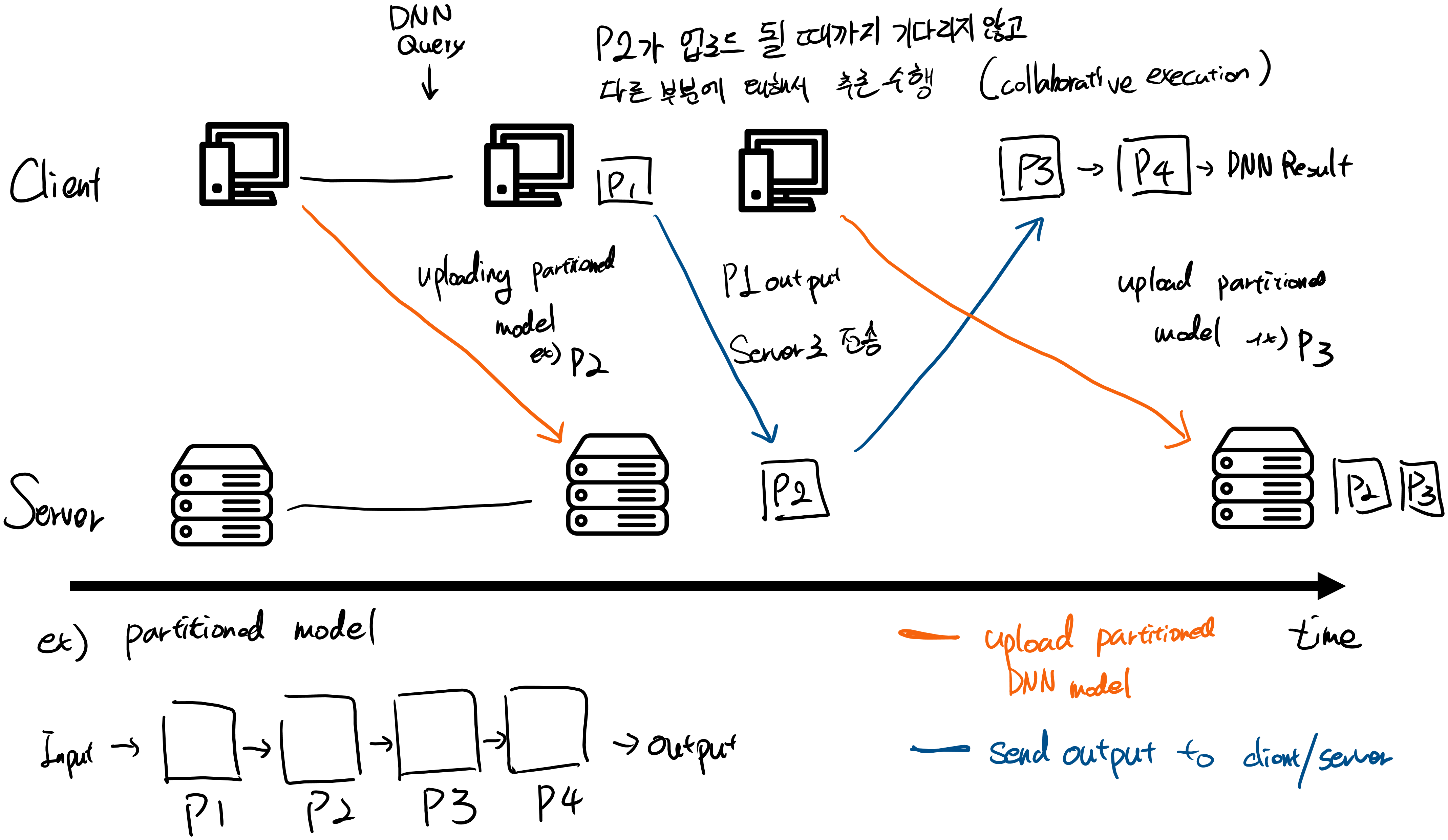
다음과 같은 과정을 거친다고 생각이 든다.
최적의 DNN partition과 업로드 순서를 결정하기 위해서 novel heuristic algorithm based on graph data structure을 제안한다.
IONN은 최단 경로 알고리즘을 이용하여 최고의 query performance를 보일 수 있는 첫번째 DNN partition을 업로드한다. 다음 DNN partition을 업로드 하기 위해서는 graph의 weight를 수정하고, 다시 최단 경로 알고리즘을 사용한다. 위를 반복하며, IONN은 DNN partition의 업로드 방법을 완벽하게 도출하고, 서버에 DNN partition이 업로드 됨에 따라서 query performance는 collaborative DNN execution을 달성하면서 best performance로 수렴하게된다.
IONN을 caffe DNN framework에 적용했고, partial DNN execution을 오프로딩하면서 DNN query performance를 향상시켰다. 또한 IONN은 DNN 모델을 upload하는 동안 더 많은 DNN query를 처리했고, embedded client가 전체 모델을 한번에 업로드 하는것 보다 효율적으로 에너지를 소비하도록 했다.
Section 2: DNN 모델을 업로드 하는데 얼마나 많은 overhead가 있는지에 대한 설명
Section 3: DNN의 간단한 리뷰, DNN offloading의 이전 연구
Section 4: IONN의 동작 방법
Section 5: partitioning algorithm의 자세한 서술
Section 6: 성능평가
Section 7: 관련 연구
Section 8: 결론
MOTIVATION
Decentralized cloud servers를 방해하는 DNN 모델 overhead 업로드에 대한 예시를 설명한다. 이 논문에서는 에지 서버를 decentralized cloud server라고 한다.
시나리오 :
- 눈이 좋지 않은 사람이 스마트 글래스를 끼고, 지하철을 탄다. 지하철 역은 붐비고, 스마트 글래스가 주변 사물을 탐지하는 것을 도와줄 수 있다. 다행이도, 지하철 역에 여러 에지서버가 (Wi-Fi Hotspots 처럼) 배치되어 있기 때문에 스마트 글래스는 에지 서버를 복잡한 DNN 계산을 근처의 에지 서버에 offloading하여 객체 인식 서비스를 가속화할 수 있다.
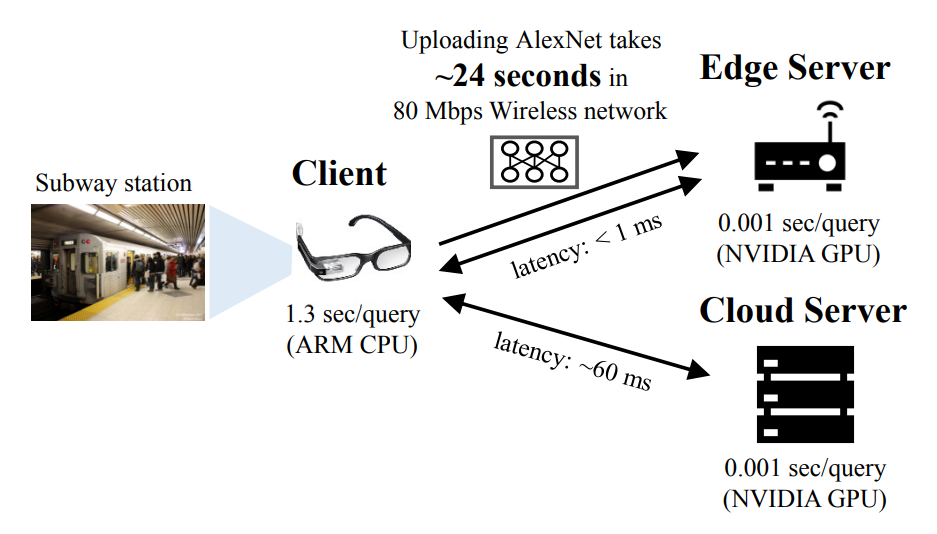
해당 시나리오는 모바일 인식 보조 (mobile cognitive assistance)의 전형적인 경우다. 스마트 글래스의 인식 보조기능은 카메라에 보이는 물체를 알려주면서 사용자를 돕는다. 이를 위해서, DNN을 이용해서 비디오 프레임에 이미지 인식(Image recognition)을 수행한다. 논문에서는 실제 장치와 네트워크에 기반한 빠른 실험을 통해 에지 서버의 실행 가능성을 확인했다.
- 장비 제원 설명, 사용한 DNN: AlexNet (Total 11 layer), bandwidth is measured about 80Mbps -
+여담: IONN에서도 정확한 bandwidth를 구하지 못했고, 측정하여 계산했다.
위 이미지는 그 결과를 보여준다. 스마트 글래스에서 DNN을 수행한 경우, query당 1.3sec가 소요되었다.
→스마트 글래스가 반드시 여러 이미지를 1초에 해결해야 하기 때문에, 1.3sec는 간신히 쓸만한 정도
에지 서버를 사용하여 DNN query를 처리하는 경우에는, 한 query당 1ms가 소요되고, 이는 Real-time 서비스를 제공할 수 있다. 하지만 DNN 모델이 에지 서버에서 사용 가능해야 하고, query를 수행할 준비가 되어있어야 한다.
랜덤한 에지 서버를 사용하기 위한 유명한 방법중 하나는 VM(Virtual Machine)-based provisioning이다. VM-based provisioning은 모바일 클라이언트가 VM으로 캡슐화된 서비스 프로그램과 환경을 에지서버에 업로드하여 (혹은 에지서버가 클라우드로 부터 다운로드 받아) 서버가 서비스 프로그램을 수행할 수 있게 하는것이다. 몇몇 최근 연구에서 가벼운 컨테이너 기술을 VM대신 사용하기도 한다. DNN offloading을 위해 해당 기술을 사용하는 경우에는 DNN 모델, DNN framework, 다른 libararies을 포함한 VM (or container) image를 업로드 해야한다. 하지만 caffe, tensorflow, pytorch같은 요즘의 상용 DNN framework는 상당한 용량(3GB 이상)을 요구하고, 이런 image를 runtime동안 업로드 하는것은 합리적이지 않다. 대신 DNN framework가 설치된 에지서버에 클라이언트가 DNN 모델만을 업로드하는것이 훨씬 합리적이다.
DNN 모델의 overhead를 확인하기 위해서, 무선 네트워크 환경에서 DNN모델의 전송시간을 측정했다. AlexNet모델을 업로드 하는데에 24초가 걸렸고, 이는 24초동안 스마트 글래스가 local에서 DNN query를 수행해야 된다는 것을 의미했고, meantime은 개선되지 않았다. 물론 네트워크 환경이 좋지 않다면 업로드 시간은 더 걸릴것이다. 만약 DNN 모델이 이미 설치된 중앙 클라우드 서버를 이용하는 경우에는 DNN query를 수행하는데 걸리는 시간이 에지 서버를 이용하는 경우와 동일했다. 그러나 네트워크 측면에서 더 긴 지연시간이 발생했다.
비록 에지 서버가 DNN query를 수행하는데 있어 매력적인 대체제지만, 실험의 결과로 사용자가 꽤 많은 시간을 에지 서버에 DNN 모델이 업로드 되기 까지 기다려야했다. 특히 에지 서버를 서비스하는 지역을 떠날 수 있는 모바일 사용자는 문제가 심각했다. 업로드가 끝나기 전에 사용자가 서비스 지역을 벗어나면 배터리만 낭비하고 네트워크를 사용했지만 에지 서버를 사용하지 않는 문제가 발생한다. 이러한 문제를 해결하기위해 IONN을 제안하며, 클라이언트가 부분 DNN 모델을 offload하며 DNN 모델이 업로드 되는 동안 부분적으로 DNN을 수행한다.
BACKGROUND
3.1 Deep Neural Network
Deep Neural Network(DNN)은 각 노드를 layer로 한다면 하나의 directed graph로 볼 수 있다. DNN의 각 layer는 입력 행렬을 어떤 operation을 통과하여 결과 행렬을 다음 layer로 넘겨준다. 어떤 레이어는 그저 고정된 parameter로 동일한 operation을 수행하지만, 학습가능한 parameter를 가지고 있는 레이어도 존재한다. 학습가능한 parameter는 말 그대로 학습 데이터와 learning algorithm을 통해 업데이트된다. 학습이 완료된 이후, DNN 모델은 하나의 파일로 deploy될 수 있고, 새로운 입력에서 결과를 얻을 수 있다(inference). caffe같은 DNN framework는 사전 학습된 DNN 모델을 파일로부터 불러올 수 있고, 새로운 데이터에 대한 inference를 수행할 수 있다. 이 논문에서는 inference를 위한 computation을 offloading하는데에 집중한다. 그 이유는 학습을 진행하는것은 inference보다 더 많은 자원을 필요로하고, 강력한 클라우드에서 학습이 진행되어야 되기 때문이다.
CNN은 Convolution 레이어를 포함한 DNN으로, 사전에 정의된 class들로 이미지를 분류하는데 널리 사용되었다. CNN에서 이미지 분류는 일반적으로 다음과 같이 진행된다.
- CNN에 이미지가 주어진다면, CNN은 convolution layer과 pooling layer를 통해 feature들을 추출한다. conv/pool 레이어는 연속적으로 연결될 수 있고, 병렬적으로 연결될 수 있다. (can be placed in series or in parallel)
- feature들을 사용해서, fully-connected layer들이 각 output class들의 점수를 매기고, softmax layer가 점수를 normalize한다.
- normalize된 점수는 이미지가 속할 수 있는 각 class의 확률로 나타내진다.
3.2 Offloading of DNN Computations
많은 클라우드 서비스는 계산량이 많은 ML 알고리즘을 수행하는 ML 서비스를 고객들에게 제공한다. 간단히 말해서 사용자는 Input 행렬을 API를 통해 클라우드에 전송하고, 서버든 그에 맞는 DNN 모델을 수행하고 결과를 고객에게 전달한다. 이러한 중앙 집중적이고, 클라우드만을 사용하는 접근법은 본 논문의 시나리오와 맞지않다.
최근 연구들은 클라이언트와 서버 두개를 이용하여 DNN 모델을 수행하는것에 대해 제안했다. NeuroSurgeon은 DNN 분할 방법을 이용한 가장 최신의 collaborative DNN execution이다. NeuroSurgeon은 DNN 모델의 각 레이어의 수행시간과 에너지 소비량을 예측하는 모델을 만들었는데, DNN 수행 profile을 통해서 회귀분석을 진행했다. 예측 모델과 runtime 정보를 사용해서 NeuroSurgeon은 동적ㅇ로 DNN을 앞부분, 뒷부분 두 단계로 나눈다. client는 앞 부분을 수행하고, output 행렬을 서버에서 전송한다. 서버는 뒷부분 모델을 수행하고, 그 결과를 client에게 전송한다. partitioning point를 결정하기 위해서 NeuroSurgeon은 모든 경우의 수를 조사하여 최적의 partitioning point를 결정지었다. 이는 서버만 사용하는것 보다 성능 향상을 가져왔다.
비록 NeuroSurgeon의 collaborative DNN execution이 효과적이었지만, 여전히 cloud 서버에 DNN 모델이 설치 되어 있는것이 가정되어 있고, 논문의 시나리오와 맞지 않다. DNN모델을 업로드 하지 않고, 분할 알고리즘이 업로드 overhead를 고려하고 있지도 않다. 하지만 collaborative execution은 좋은 insight를 주었다. 따라서본 논문은 DNN 모델을 나눌 수 있고, 각 부분을 점진적으로 업로드 할 수 있다. 결국 client와 server는 각 부분을 모든 모델이 업로드 되지 않더라도 수행할 수 있다. 이 insight를 통해서, 새롭고정교하고 유연한 분할 알고리즘과 더욱 점진적인 DNN 수행의 offloading을 디자인했다.
4 IONN FOR DNN EDGE COMPUTING
여기에선 DNN 계산을 위한 에지 서버를 이용한 offloading 시스템인 IONN을 제안한다.
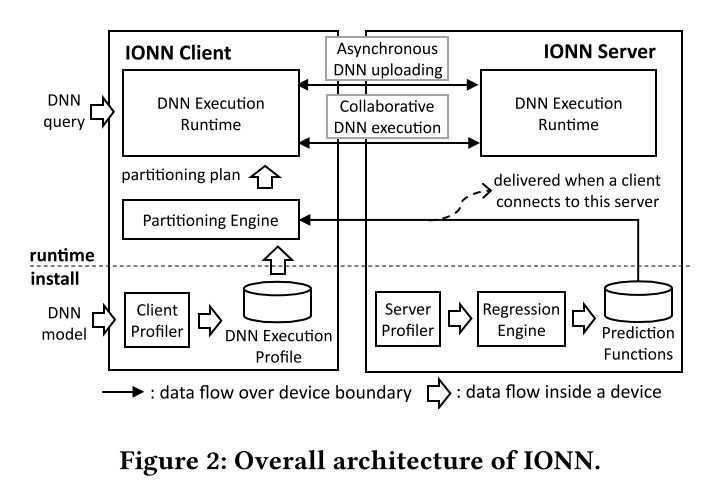
Figure 2는 2단계로 이뤄진 전체적인 IONN의 구조를 설명한다. install phase에서는 IONN은 DNN layer의 execution profile을 수집한다. runtime phase에서는 IONN은 install phase에서 얻은 execution profile과 동적인 네트워크 상태에 기반하여 DNN partition과 업로드 순서를 결정하는 업로딩 계획을 생성한다. 업로딩 계획에 기반하여 client는 DNN partition을 비동기적으로 background thread를 이용해서 업로드한다. 새로운 DNN query가 발생한 경우, IONN은 client와 sever에서 partition이 업로드 되지 않았더라도 collaboratively 수행한다.
Install Phase (Client)
모바일 장치에 DNN application이 설치되어 있으면, IONN client는 DNN 모델을 수행하고, 각 DNN layer의 execution time을 DNN execution profile라는 파일에 기록한다.
Install Phase (Server)
에지 서버는 어떤 DNN 모델을 수행할 지 모르기 때문에, 서버에서 DNN execution profile을 수집하는것은 적절하지 않다. 대신 IONN Server을 설치할 경우 DNN layer의 parameter과 type에 따라 서버에서 execution time을 estimate하는 prediction function을 만들었다. prediction function은 runtime때 client로 보내지고, client는 이를 DNN을 나누는데 사용한다. prediction function을 생성하기 위해서 IONN Server는 NeuroSurgeon이 그랬던 것처럼 다양항 DNN 모델과 다양한 layer parameter을 이용한 linear regression을 수행한다. NeuroSurgeon에서 list한 regression function을 사용했고, 언급되어있지 않은 layer는 input size를 이용하여 사용했다.
Runtime Phase
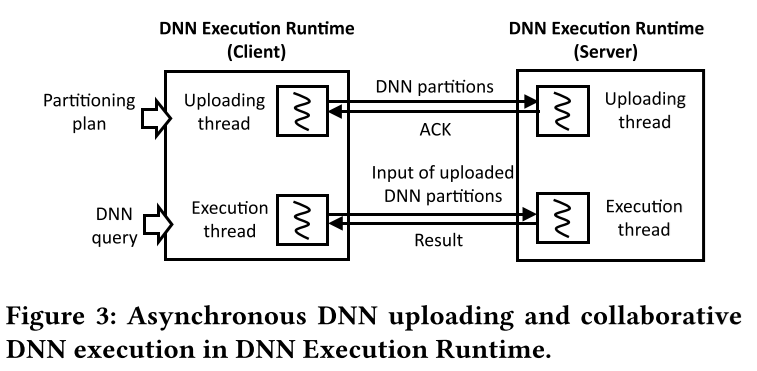
- Runtime phase는 모바일 client가 에지 서버의 서비스 영역에 들어오면 시작된다.
- client가 에지 서버와 연결을 확립하면 에지 서버는 서버의 prediction function을 client로 전송한다. prediction function의 size가 작기 때문에 이를 보내는 network overhead는 무시가능하다.
- client가 prediction function을 전송받은 후, client의 partitioning engine이 graph-based partitioning algorithm을 이용해서 업로딩 계획을 생성한다.
- DNN Execution Runtime은 DNN partition을 업로딩 계획에 기반하여 업로드 하고, 동시에 collaborative DNN execution을 DNN query 요청에 따라 수행한다.
- DNN Execution Runtime이 DNN partition을 업로드하고, DNN query를 동시에 수행해야 하기 때문에 2개의 thread가 필요하다. 하나는 업로드, 하나는 수행을 위해서.
Client의 uploading thread는 업로딩 계획이 생성 되자마자 시작된다.
- 먼저 uploading thread는 첫번째 DNN partition을 서버에 전송한다
- 서버는 도착한 DNN partition으로 DNN 모델을 생성하고, ACK를 client에게 전송한다.
- Client의 uploading thread는 다음 partition을 서버에 전송한다.
- 이 uploading 과정을 마지막 DNN partition이 서버에 업로드 될 때까지 반복한다
Execution thread는 현재 DNN partition의 업로드 상태에 따라 DNN query를 수행한다. Client는 ACK를 통해 어떤 partition이 서버에 업로드가 완료되었는지 알 수 있다. 여기에서 현재 서버에 업로드된 partition을 uploaded partition, 아닌 부분을 local partition이라 하자.
- DNN query가 발생하면, execution thread는 upload partition 전까지 local partition을 수행하고, uploaded partition의 인덱스 번호와 그 결과를 서버에 전송한다.
- server는 전송받은 인덱스 번호에 맞는 upload partition의 DNN layer을 수행하고 결과를 client에 전송한다.
- Client와 server는 위 방법을 output layer을 수행할때 까지 반복한다.
5 DNN PARTITIONING
여기에선 PARTITIONING ENGINE이 업로딩 계획을 생성하는 방법에 대해 설명한다.
IONN의 partitioning algorithm은 최대한 빠르게 최고의 query 성능을 얻기 위해서 서버에 필요한 DNN layer들을 업로드 하고자 노력한다. 하지만 모든 레이어를 한번에 업로드하지 않고, 한 partition을 한번에 업로드 하기 때문에 query는 업로드 중에 발생할 수 있고, 이미 업로드 된 partition은 collaborative하게 수행될 수 있다. 이를 위해 알고리즘은 DNN 레이어를 성능적 이득과 각 레이어의 업로드 overhead를 고려하여 분할하여 계산량이 많은 레이어가 먼저 업로드 되도록 한다. 이런 업로딩 계획을 달성하기 위해, graph-based DNN execution 모델을 만들었고, 이를 NN execution graph로 이름짓고 DNN partition을 iteratively 가장 빠른 execution path를 찾아가며 생성했다.
5.1 Neural Network (NN) Execution Graph
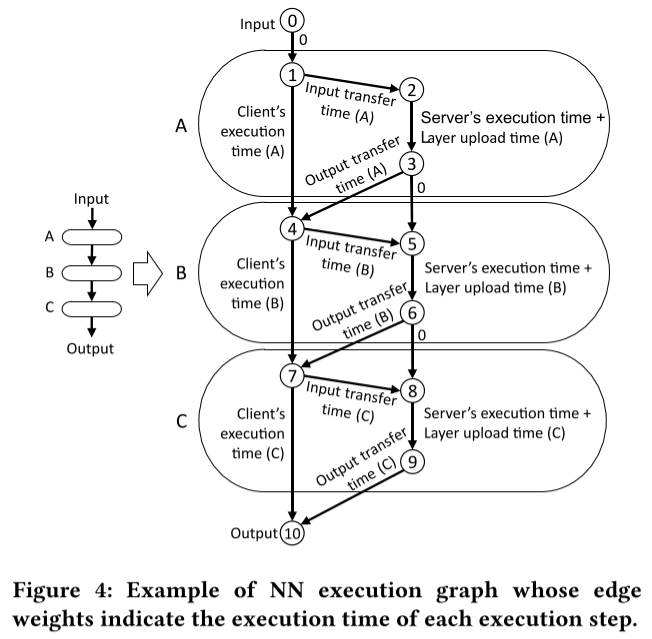
NN execution graph는 layer level에서 client와 server의 collaborative execution path를 나타낸다.
각 레이어는 3개의 노드로 변환되어 나타내진다 (layer A: 1,2,3, layer B: 4,5,6, layer C: 7,8,9). 좌측의 노드(0,1,3,7,10)는 client에 속해 있는 경우이고, 오른쪽에 있는 노드(2,3,5,6,8,9)는 서버에 속해 있는 경우를 나타낸다. client 노드를 연결하는 에지(1→4)는 local execution을 나타내고, 같은 레이어 안에 있는 서버 노드를 연결하는 에지(2→3)는 server execution + 레이어 업로드 시간을 의미한다. client 노드와 server 노드를 연결하는 에지(1→2 또는 3→4)는 input이나 output 행렬을 네트워크를 통해 전송하는것을 나타낸다. 각 에지는 해당하는 overhead에 따라 weight가 부여되어있다. 어떤 에지는 weight가 0인데 (0→1 또는 3→5) 이는 어떤 계산도 전송 overhead도 포함되어 있지 않기 때문이다. client는 에지의 weight를 다음과 같이 설정한다.
- client는 local layer execution time을 DNN execution profile로, server's layer execution time을 prediction function으로 얻어낸다.
- 또한 data와 layer 전송 시간은 전송할 데이터의 크기를 네트워크 속도로 나누어서 계산할 수 있다.
DNN query의 execution path를 그래프에서 나타낼 수 있다. DNN query가 발생했다고 가정하자(0→1). 만약 layer A가 client에서 수행된다면, execution flow는 바로 layer B로 가게 된다(node 1→4), 혹은 client가 layer A의 수행을 offload한다면 execution flow는 node 2에서 3으로 가게된다. 만약 다음 layer (layer B)가 역시 서버에서 수행도니다면 execution flow는 노드 3에서 노드 5로 가게된다. 혹은 layer B가 client에서 수행된다면, exectuion flow는 노드 4로 가게 된다. 이러한 방식으로, DNN query의 execution path를 그래프에서 나타낼 수 있고, input(노드 0)에서 output(노드 10)까지의 경로는 모든 DNN layer을 수행한 execution path를 나타낸다. 예를 들어, Figure 4에서 경로가 0→1→4→5→6→7→10이라면 client는 layer A를 수행하고, layer B를 offload 하고, layer C를 다시 수행하게 된다.
input에서 output까지의 경로에서 그래프의 에지 weight의 합은 경로에서 query execution time과 DNN을 서버에 업로드하고 수행한 시간의 합을 나타낸다. 예를 들어, Figure 4에서 경로가 0→1→4→5→6→7→10인 경우 layer A와 C를 client가 수행하는 시간과 layer B를 서버에서 수행하는 시간, feature data (input 또는 output 행렬)를 전송하는 시간, 그리고 layer B를 업로드 하는 시간이 포함된다. 따라서 NN execution graph에서 최단 경로를 계산한다면, 해당 경로는 어떤 layer가 먼저 서버에 업로드 되어야 query execution time을 최소화 하는지 알려준다.
5.2 Partitioning Algorithm
IONN의 DNN partitioning 문제는 어떤 레이어를 업로딩 partition에 포함할 것인지 결정하는 것과, 어떤 순서로 업로드 할 것인지, query execution time을 최소화 하도록 결정해야 한다. 불행히도, 미래의 query를 완전히 알지 않는 한 optimal solution을 찾는것은 불가능 하다. 어떤 partition을 optimal 하게 업로드 하려면 다음 query가 언제쯤 발생하는지 알아야 하기 때문이다. client의 미래 query 패턴을 예측하는것은 어렵기 때문에 두개의 규칙에 기반한 irrespective한 패턴에서 동작하는 heuristic algorithm을 제안한다.
- DNN layer의 performace benefit이 높고 overhead가 낮은 layer을 우선적으로 업로드한다. 이는 서버가 빠르게 apartial DNN을 빠르게 만드는데 도움을 주고, query performace를 더 빨리 향상시킬 수 있다.
- 불필요한 DNN layer는 업로드하지 않는다. 성능 향상에 영향을 주지 않는 layer들은 offloading cost를 줄이기 위해서 업로드 하지 않는다.
IONN의 알고리즘은 NN execution graph의 최단 경로 알고리즘에 기반을 두고 있다. 위에서 말했던 것처럼, 초기 상태(layer가 업로드 되지 않은)의 NN execution graph에서 최단경로는 DNN query를 처리할 때 가장 빠른 execution path이다.반면에, DNN layer들의 upload time을 0으로 할 경우 graph는 전체 DNN model이 업로드 된 경우를 나타내고, 이는 DNN execution을 offloading 했을 경우의 optimal state를 나타낸다. 이러한 그래프에서 최단 경로를 계산한다면, 그 경로는 최고의 query performance를 제공하는 execution path이고 collaborative execution을 달성할 수 있다<항상 모든 layer가 server에서 수행 될 필요는 없다. 가끔 어떤 레이어는 전송 overhead가 너무 크기 때문에 전송하지 않고 client에서 수행하는것이 좋다>. 최고의 성능에 도달하기 위해서, 에지의 weight를 초기 상태에서 optimal 상태까지 변하도록 iterative하게 NN execution graph에서 최단 경로를 계산하는 업로딩 플랜을 만들었다.

- Algorithm 1은 처음에는 비어있는 list인 DNN partition list (partitions)인 uploading plan을 계산하는 IONN의 DNN partitioning algorithm을 설명한다. (line 2)
- 먼저 DNN model description, DNN execution profile, prediction function, 현재 network speed를 이용해서 NN execution graph를 만든다.(line 4)
- NN execution graph의 input에서 output까지의 최단 경로를 탐색한다 (line 6)
- 이후 최단 경로에 서버 쪽의 노드가 포함되어 있는지 확인하고, DNN partition을 생성하고 그 layer들을 합쳐서 partitions에 추가한다.(line 7)
- 최단 경로의 계산에 layer execution time과 layer upload time을 포함하고 있기 때문에 DNN partition은 속도도 빠르고 업로드 시간도 짧은 layer를 포함하며, 첫번째 규칙을 만족한다.
- DAG에서 사용되는 topological sorting을 이용한 최단 경로 알고리즘을 사용할 수 있고, 복잡도는 O(n)이다.
- 이후, layer upload time에 K(1보다 작은 양수)를 곱하여 layer upload time을 줄인다.(line 8)
- 업데이트된 그래프에서 새로운 최단 경로를 탐색한다(line 6)
- layer uploading time이 줄었기 때문에 더 많은 서버 쪽의 노드가 최단 경로에 포함될 수 있다.
- 이후 최단 경로에 새롭게 추가된 서버 쪽의 노드를 포함한 레이어로 다음 DNN partition을 생성한다.
- 이 과정을 layer upload time의 weight가 거의 0에 가까워 질 때까지 반복한다.(line 5) 이는 offloading 할 경우의 optimal state와 유사하다.
- 따라서, query performance가 마지막 partition을 업로드 한 이후 최고의 성능을 달성하며 두번째 규칙도 만족한다.
알고리즘의 output은 DNN partition의 list이고, client는 list에 따라서 처음부터 마지막까지 업로드를 진행한다.
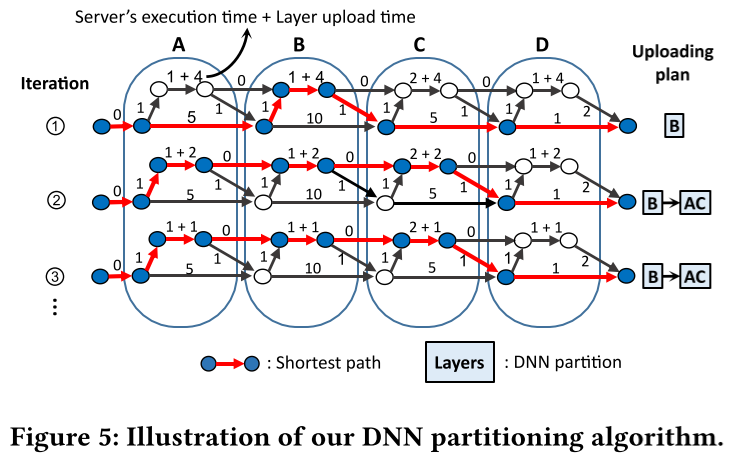
Figure 5는 IONN의 partitioning algorithm을 4개의 layer로 이루어진 DNN(A~D)으로 예시를 보여준다.
- 먼저 5.1에서 설명했던 것처럼 초기 상태인 NN execution graph를 생성한다.
- 첫번째 iteration에서 그래프의 input에서 output까지의 최단 경로를 탐색하고, DNN partition [B]를 만든다 (layer B만 서버쪽에 있기 때문).
- 이후 K (이 예시에서는 0.5)를 layer upload time에 곱한다
- 다음 iteration에서 새로운 최단 경로를 탐색한다. 그리고 두번째 DNN partition [A,C]를 만든다 (layer A와 C가 최단 경로에서 새롭게 서버쪽에 포함되었기 때문).
- 세번째 iteration에서 최단 경로는 layer upload time이 절반이 되었음에도 이전과 동일한 경로를 갖는다. 때문에 새로운 DNN partition이 생성되지 않는다.
- 결국 layer D는 절대 업로드 되지 않는다. layer upload time이 0이 될지라도 최단 경로에 layer D는 서버쪽에 포함되지 않기 때문이다. → 이 뜻은 layer D는 client에서 수행되는 편이 최고의 query performance를 낸다는 것이다.
따라서 IONN의 알고리즘은 uploading plan ( partitions = [ [B], [A,C] ] )을 생성한다. uploading thread는 layer B를 먼저 업로드하고, 그 다음에 A와 C를 업로드 한다. 이 방식으로, IONN은 빠르게 계산이 많은 layer (B)를 먼저 업로드 하고 결과적으로 layer (A, B, C)를 업로드하여 최고의 query performance를 달성한다. 또한 layer D를 업로드 하지 않으며 client의 에너지 소비를 절감한다.
DNN partition을 K값을 변화시키며 세분화 할 수 있다. 만약 K값이 작은 경우, layer upload time의 weight는 iteration마다 빠르게 감소할 것이다. 이는 partitioning algorithm이 적은 iteration으로 빨리 끝나게 하고, 개수는 적지만 크기가 큰 DNN partition들을 만든다. 반면 K값이 큰 경우 많은 iteration과 개수가 많고 크기가 작은 DNN partition들을 만든다. Section 6에서 K의 영향을 확인한다.
IONN의 알고리즘은 에지 서버가 네트워크와 컴퓨팅 자원을 많이 갖고 있는것을 가정한다. 따라서 공유된 에지 서버간의 연결과 여러 client와 연결된 자원은 무시한다. 여러 client와 한정된 에지 서버 자원인 경우의 partitioning algorithm은 추후 계획으로 남겨둔다.
5.3 Handling DNNs with Multiple Paths
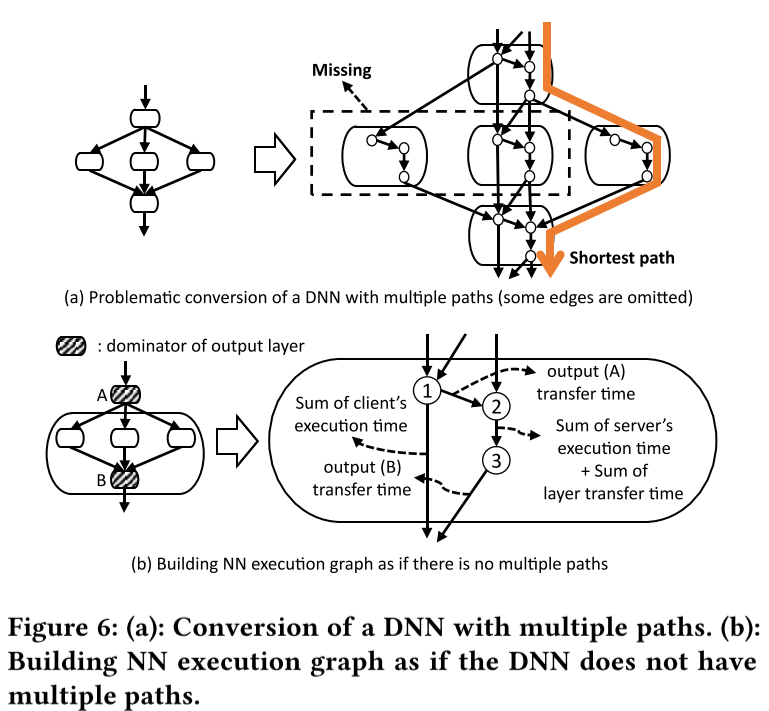
IONN의 partitioning algorithm으로 DNN을 다루는데에는 여러 경로가 나오는 문제가 있다. Figure 6는 알고리즘이 올바르게 동작하지 않는 경우를 보여준다. 이 예시는 Neural Network가 세 개의 레이어로 output을 전달하고 그 세개의 레이어의 output이 concatenate되어 다음 레이어의 input으로 주어진다(Figure 6 (a) 의 좌측 그림). 만약 Figure 4에서 했던것 처럼 각 레이어를 하나씩 NN execution graph로 바꾼다면, Figure 6 (a)의 우측과 같이 된다. 이 그래프에서, input에서 output까지의 최단 경로는 세 레이어중 하나의 레이어만 최단 경로에 포함되고 나머지 두 layer는 누락된다. 불완전한 execution path로 인하여 올바르지 못한 업로딩 플랜을 야기한다.
이 문제를 해결하기 위해서 Figure 6 (b)와 같이 NN execution graph를 multiple path가 없는것 처럼 만들었다. 먼저 output layer의 dominator들을 찾는다. dorminator는 input과 output까지의 최단 경로에서 반드시 포함되어야 하는 layer다. 이후, NN execution graph를 만들 때 두 개의 dorminator 사이의 layer들(A와 B사이의 layer들)을 뒤에 있는 dorminator(B)와 하나의 레이어로 묶었다. 합쳐진 layer의 에지 weight는 Figure 6 (b)의 우측에서 볼 수 있다. 결국 dorminator를 지나가지 않는 경로는 없게되며 (dorminator의 정의에 의해), input에서 output 까지의 최단 경로에서 어떤 layer도 누락되지 않는다.
IONN은 network bandwidth를 측정하여 계산했다.
IONN은 client-server 두 대의 device로 구성되어 있다.
Install Phase와 Runtime Phase로 구성되어 있다.
각 phase는 thread를 이용하여 작동한다.
layer upload time에 K를 곱하여 계속 줄어드는 이유?
논문을 읽으면서는 최대한 overhead가 큰 layer을 업로드 하고, 이후로는 작은 layer을 업로드 하기 때문일 것이라고 생각했으나, K는 그저 partitioning plan을 만드는데 있어서 완급 조절을 해주는 것이라고 생각들었다.
실제 layer upload time이 줄어드는 것이 아니라, K를 곱해가며 iteration 횟수를 줄이고 partition의 크기를 크게하여 네트워크 overhead를 크게 할지, iteration 횟수를 늘리고 partition의 크기를 작게하여 네트워크 overhead를 작게 할지 결정하는것 같다.
server에서 수행시간을 예측하기 위해서 prediction function을 사용했다.
DNN model description, DNN execution profile, prediction function, 현재 network speed를 이용해서 NN execution graph를 생성하여 partitioning plan을 만들었다.
하다보니 리뷰가 아니고 번역이 되어버린것 같다...
'논문리뷰' 카테고리의 다른 글
| MoMask: Generative Masked Modeling of 3D Human Motions (0) | 2024.11.01 |
|---|---|
| MotionGPT: Human Motion as a Foreign Language (2) | 2024.10.23 |
| PET (Point quEry Transformer) 코드 (0) | 2024.03.14 |
| Adaptive Parallel Execution of Deep Neural Networks on Heterogeneous Edge Devices (0) | 2023.02.15 |
| [논문리뷰]Mastering Atari, Go, chess and shogi by planning with a learned model - MuZero_서론 (1) | 2021.08.10 |


