Abstract
pre-train된 Large Language Model들이 나타나며, 언어와 multimodal 데이터를 통합한 모델을 만드는 것이 여전히 챌린지로 남아있다.
- Though the advancement of pre-trained large language models unfolds, the exploration of building a unified model for language and other multimodal data, such as motion, remains challenging and untouched so far.
바디랭귀지처럼, human motion은 언어와 의미적으로 비슷함.
언어모델과 large-scale motion 모델을 융합해 모션과 언어의 관계를 학습하는 사전학습이 가능해짐.
- Fortunately, human motion displays a semantic coupling akin to human language, often perceived as a form of body language.
- By fusing language data with large-scale motion models,motion-language pre-training that can enhance the performance of motion-related tasks becomes feasible.
Motion과 관련된 task들을 다루기 위해 MotionGPT 제안
- Driven by this insight, we propose MotionGPT, a unified, versa tile, and user-friendly motion-language model to handle multiple motion-relevant tasks.
MotionGPT의 특징으로는 discrete vector quantization으로 3D 모션을 token으로 변환함.
”motion vocabulary”를 활용해 사람의 motion을 하나의 특정 언어로 다룸 → 모션과 언어 통합
- Specifically, we employ the discrete vector quantization for human motion and transfer 3D motion into motion tokens, similar to the generation process of word tokens.
- Building upon this “motion vocabulary”, we perform language modeling on both motion and text in a unified manner, treating human motion as a specific language.
Prompt learning으로 영감을 받아, MotionGPT를 motion-language data를 사용해 prompt-based Q&A로 fine-tune 진행
- Moreover, inspired by prompt learning, we pre-train MotionGPT with a mixture of motion-language data and fine-tune it on prompt-based question and-answer tasks.
# Abstract 정리
- 언어-multimodal 데이터 통합 모델 어려움
- human motion은 일종의 언어로 볼 수 있음(바디랭귀지)
- 모션과 언어의 관계를 학습하는 사전학습이 가능
- 이를 위해 3D motion을 token으로 변환 (discrete vector quantization)
- "motion vocabulary"를 활용해 motion과 언어 통합1. Introduction
GPT, BERT, T5 등 다양한 언어, 이미지, mesh, multimodal 모델이 나왔지만, human motion과 언어를 합친건 나오지 않았다.
- Recent years have witnessed a significant breakthrough in pre-trained large language models such as GPT[34, 35, 3, 27], BERT [7], and T5 [36, 5], which lead to the convergence of language [59, 47], image [33, 50, 20], mesh [55, 26] and mutlimodal [8] modeling.
최근 text-to-motion연구는 pre-trained language-relevant 모델을 사용하려고 시도함.
- Recent text-to-motion works have attempted to employ pre-trained language-relevant models.
MDM
- CLIP의 conditional text token으로부터 motion diffusion을 학습하는 모델
- MDM [46] learns a motion diffusion model with conditional text tokens from CLIP
MLD
- motion latnet space를 통합해 motion diffusion process의 성능을 높임
- MLD [52] integrates motion latent space to improve the efficiency of motion diffusion process.
MotionCLIP and TM2T
- motion과 text 표현상의 관계를 모델링함
- MotionCLIP [45] and TM2T[11]concentrate onmodelingthe coupled relationship between motion and text description.
하지만 위 연구들은 motion과 text를 나눠서 다룸.
- However, the above approaches treat motion and language as separate modalities, which often require strictly paired motion and text data.
게다가, task에 맞춰 학습을 진행해 일반화하기 어렵고, motion과 language의 관계에 대한 이해가 부족하다.
- Moreover, since the supervisions are task-specific, they can hardly generalize effectively to unseen tasks or data, as they lack a comprehensive understanding of the relationship between motion and language.
다양한 task에 일반화되고, motion과 language의 관계를 깊게 학습한 pre-trained motion-language model에 집중.
- We thus focus on building a pre-trained motion-language model, which can generalize to various tasks and learn in-depth motion-language correlation knowledge from more feasible motion and language data.
두 가지 challenge
- motion과 language의 관계 모델링하기
- 통합된 multi-tsk 프레임워크 만들기
- The first is modeling the relation between language and motion, and the second is building a uniform multi-task framework that can generalize to new tasks.
바디랭귀지와 같이 motion이 의미적으로 언어와 비슷한 것을 바탕으로, BEiT-3와 같은 vision-language pre-training과 유사하게 human motion을 하나의 특정한 외국어로 취급
- Building upon this observation,we follow vision-language pre-training from BEiT-3 to treat human motion as a specific foreign language.
motion과 language를 통합해 single vocabulary로 인코딩해 motion과 language의 관계를 더욱 명확하게 함.
- By integrating motion and language data together and encoding them within a single vocabulary, the relationship between motion and language becomes more apparent.
MotionGPT: 통합된 motion-language 프레임워크 제안. pre-trained language model의 강력한 language 생성과 zero-shot transfer 능력의 이점을 활용
- In this work, we propose a uniform motion-language framework, namely MotionGPT, that leverages the strong language generation and zero-shot transfer abilities of pre-trained language models for doing human motion-related tasks.
- VQ-VAE 모델 학습 및 “motion vocabulary” 구성
- first learn a motion-specific vector quantized variational autoencoder (VQ-VAE) model to construct “motion vocabulary”, akin to English vocabulary and then convert raw motion data into a sequence of motion tokens.
- 향후 이 토큰을 통해 motion language의 숨겨진 문법, 문맥등을 학습
- These tokens are then processed by a pre-trained language model [36, 5] that learns the underlying grammar and syntax of the motion language, as well as its relationship with the corresponding textual descriptions.
- 효과적으로 motion과 language를 통합하기 위해 훈련을 2단계로 나눠 진행.
- To effectively integrate language and motion in MotionGPT, we design a two-stage training scheme.
- Pre-train Language Model 단계: Raw motion dataset으로 language model이 motion language의 문법, 문맥 학습
- We first pre-train the language model on the raw motion dataset to learn the basic grammar and syntax of the motion language.
- Prompt tuning 단계: motion과 text가 포함된 instruction dataset으로 fine-tune을 진행해 두개의 modality의 상관 관계 학습
- For prompt tuning, we fine-tune the language model on an instruction dataset, which contains both textual descriptions and motion data, to learn the correlation between the two modalities.
Contribution 요약
- motion을 외국어처럼 다루는 MotionGPT(통합된 motion-language 생성 pre-trained model)제안.
- (1) We propose a uniform motion-language generative pre-trained model, MotionGPT, which treats human motion as a foreign language, introduces natural language models into motion-relevant generation, and performs diverse motion tasks with a single model.
- Instruction tuning으로 motion-language 학습 방식 도입
- (2)We introduce a motion-language training scheme with instruction tuning, to learn from task feedback and produce promising results through prompts.
- Multi-task evaluation을 위한 벤치마크 제안.
(text-to-motion, motion-to-text, motion prediction, motion in-between)- (3) We propose a general motion benchmark for multi-task evaluation, wherein MotionGPT achieves competitive performance across diverse tasks, including text-to-motion, motion-to-text, motion prediction, and motion in-between, with all available codes and data.
# Introduction 정리
- 기존 모델은 text와 motion을 따로 취급했다
- human motion과 언어를 통합한 모델이 없었다
- motion을 하나의 새로운 언어로 취급해, 하나의 통합된 vocabulary를 만들었다
- 최종적으로, 통합된 motion-language 프레임워크인 MotionGPT를 제안한다2. Related Work
Human Motion Synthesis(Human motion 합성)
multi-modal inputs
- text
- action
- incomplete motion
Generating diverse human-like motion
- HumanMotion Synthesis involves generating diverse and realistic human-like motion using multi modal inputs, such as text, action, and incomplete motion.
Text-to-motion
MDM
- Diffusion base 생성모델
- 다양한 motion task에 대해 나눠서 학습됨
- MDM [46] proposes a diffusion-based generative model [14] separately trained on several motion tasks.
- CLIP의 conditional text token으로부터 motion diffusion을 학습하는 모델
- MDM [46] learns a motion diffusion model with conditional text tokens from CLIP
Q. 각 motion task에 따른 다른 생성 모델이 존재한다는 뜻인가?
MDM 간단하게 확인 필요
MLD
- latent diffusion model
- conditional inputs에 따라 motion 생성
- MLD [52] advances the latent diffusion model [43, 38] to generate motions based on different conditional inputs.
T2M-GPT
- VQ-VAE와 GPT를 기반으로 한 생성 프레임워크 연구
- T2M-GPT [57] investigates a generative framework based on VQ-VAE and Generative Pre-trained Transformer (GPT) for motion generation.
- 문득 드는 생각 -
계속 반복적으로 나오는 pre-trained model은
transformer를 의미하고, 각 입력 혹은 vocab의 관계(attention)을
사전학습한 모델임을 뜻하고 있는건가?Motion completion task
고전적인 motion 생성 처럼 partial motion을 조건으로 motion 생성
motion의 시작과 끝을 고정하고, 그 사이의 중간 motion을 생성하는 in-between 방식
- Motion completion task generates motion conditioning on partial motions, such as classical motion prediction [56, 61, 24] or motion in-between [46], which generates the intermediate motion while the first and last parts are fixed.
위 모델들의 한계점
- 여러 task를 다루기 위한 단일 모델을 만드는데 한계가 있었다.
- Although they show promising results in various human motion tasks, most above methods are limited in using a single model to handle multiple tasks.
따라서, 통합된 접근법을 제안한다.
- human motion을 외국어(foreign language)로 취급
- 언어 생성과 zero-shot transfer에 강력한 pre-trained language model을 활용한다
- We thus propose a uniform approach that treats human motion as a foreign language, and leverages the strong language generation and zero-shot transfer abilities of pre-trained language models
Human Motion Captioning
사람의 motion을 자연어로 표현하기 위해서는 두 가지의 통계적 model을 사용해 motion을 language에 mapping하는 것을 학습했다.
- To describe human motion with natural languages, [44] learns the mapping from motions to language relying on two statistical models.
- 새로운 motion representation 제안
- motion을 짧은 discrete variable로 압축
- neural translation network를 통해 motion과 language의 관계 mapping
- TM2T [11] proposed a new motion representation that compresses motions into a short sequence of discrete variables, then uses a neural translation network to build mappings between two modalities.
- TM2T가 captioning module을 training pipeline에 통합했으나, text → motion, motion→text 양방향 번역으로만 제한되어있었다.
- While previous research like TM2T [11] incorporated captioning modules into their training pipeline for motion generation, these approaches are constrained to bidirectional translation between text and motion within one uniform framework.
- 새로운 motion representation 제안
TM2T
Language Models and Multi-Modal
방대한 데이터셋과 거대한 모델 크기로 구성된 LLM은 인상적인 이해력과 생성 능력을 입증하며, 자연어 처리의 수준을 새로운 높이로 끌어올렸다.
- Large-scale language models (LLMs) [7, 6, 36, 3, 59, 47], enabled by extensive datasets and model size, have demonstrated impressive comprehension and generation capabilities, elevating natural language processing to new heights.깊은 양방향 언어 표현을 사전 학습해 구체적으로 해결하고자 하는 문제(downstream task)를 지원한다.
- BERT [7] pre-trains deep bidirectional language representations that can support downstream tasks.모든 text-base 언어 문제를 text-to-text 포맷으로 변경해 하나의 프레임워크로 통합
T5- T5 [36] introduced a unified framework that converts all text-based language problems into a text-to-text format.
- 최근 연구에 따르면, pre-trained된 모델을 instructions과 정답이 결합된 input-output pair를 사용해 fine-tuning하면, 모델의 성능이 향상됨을 발견
- More recent research [51, 2, 27, 5] find that by fine-tuning pre-trained models using input-output pairs consisting of instructions and coupled answers, the performance of pre-trained models can be further improved.처음 보는 task에 대해 instruction-tuning 기법을 적용해, 튜닝되지 않은 모델의 성능을 초과
FLAN- FLAN [5] presents an instruction-tuning technique that surpasses the performance of non-tuned models in unseen tasks.
- 최근, multi-modal 모델들이 이미지, 오디오, 비디오 등 다른 modality와 text를 함께 처리하는데 관심이 쏠리고 있다.
- Recently, the wave of multi-modal models [20, 15, 19] is intriguing to process text along with other modalities, such as images [20, 15, 8], audio [13, 8], and videos [53].이미지와 이미지에 해당하는 언어 설명을 연결하는 의미적 잠재 표현(semantic lantent representation)을 학습
CLIP- CLIP [33] further learns a semantic latent representation that couples images with corresponding language descriptions.
BERT
다양한 언어 모델이 vision-language task에서 성공이 있었지만, human motion-language multi-modal 모델은 여전히 한계가 있음
- Despite the success of language models in various vision-language tasks, the development of multi-modal language models that can handle human motion is still limited.
Motion Language Pre-training
기존의 text-to-motion generation 방법은 model에게 원하는 motion을 묘사한 텍스트를 제공하는 caption-to-motion으로 특정된다.
- Existing text-to-motion generation methods [10, 30, 46, 11, 1, 17] can be characterized as caption-to-motion, where the models take in a pure text description of the desired motion.
기존 방법은 motion을 생성할 수 있지만, InstructGPT처럼 사용자의 지시(instruction)를 지원하는데에 한계있다.
즉, 사용자가 context-specific한 instruction을 제공하는것을 허용하지 않는다.
- While these methods can generate motions from textual descriptions, they are often limited in supporting instructions from users like InstructGPT [27].
- In other words, they do not allow users to provide context-specific instructions for certain applications.CLIP의 언어와 vision의 이해를 활용해, motion auto-encoder로 latent space에 motion을 위치시켰다.
- MotionCLIP [45] utilizes the language and visual understanding of CLIP [33] to align its latent space with a motion auto-encoder.
MotionCLIP
반면, T5나 InstructGPT와 같은 많은 언어 모델들은 번역, 질의응답, 분류와 같은 다양한 언어 처리 작업을 해결하도록 발전했다.
이러한 모델들은 주어진 text input과 target output을 map하도록 디자인되었다.
하지만 이런 모델들은 언어 작업에서 엄청난 성능을 보여줬지만, motion task에서는 널리 적용되진 않았다.
- Meanwhile, many language models, such as T5[36] and InstructGPT [27], have been developed to address diverse language processing tasks, including translation, question answering, and classification.
- These models are typically designed to map a given text input to a target output, such as a translation or answer.
- However, while these models have shown remarkable performance in language tasks, they have not been widely applied to motion tasks.
human motion task와 자연어 모델의 통합을 가능토록 하며, motion 합성 문제에 대해 통합된 해결책을 제공하는 MotionGPT를 제안한다.
- Therefore, we propose MotionGPT to enable the effective integration of natural language models with human motion tasks, providing a unified solution for motion synthesis problems
# Related Work 정리
- Human motion synthesis
- Text-to-Motion / Motion Completion Task
- 여러 task를 다루기 위한 단일 모델로써 한계점 존재
- Human motion을 하나의 "언어"로 취급(foreign language)
- pre-trained language model 활용
- VQ-VAE가 처음 언급됨.(T2M-GPT)
- Human Motion Captioning
- 기존: 두 가지 통계적 모델을 사용해 motion과 language mapping
- T2MT: Motion을 짧은 Discrete Variable로 압축
- Language Models and Multi-Modal
- BERT, T5, FLAN, CLIP
- T5의 경우 모든 text-base 언어 문제를 Text-to-Text 포맷으로 변경
- 언어모델이 vision-language에서는 성공했으나, motion-language는 제한적
- Motion Language Pre-training
- 기존: 원하는 motion을 묘사한 text를 제공하는 Caption-to-Motion
- T5, InstructGPT 같은 모델은 input과 output pair를 통해 다양한 언어 작업을 해결하도록 발전
- Human motion task와 자연어 모델의 통합 - MotionGPT
MotionGPT에서 차용한 것들
1. VQ-VAE와 discrete quantization으로 motion token화
2. T5가 모든 문제를 Text-to-Text로 학습했기에, motion token을 사용해 pre-train 진행
3. Instruction Pair를 사용해 다양한 task (M2T, T2M, motion prediction, in-between) 수행3. Method
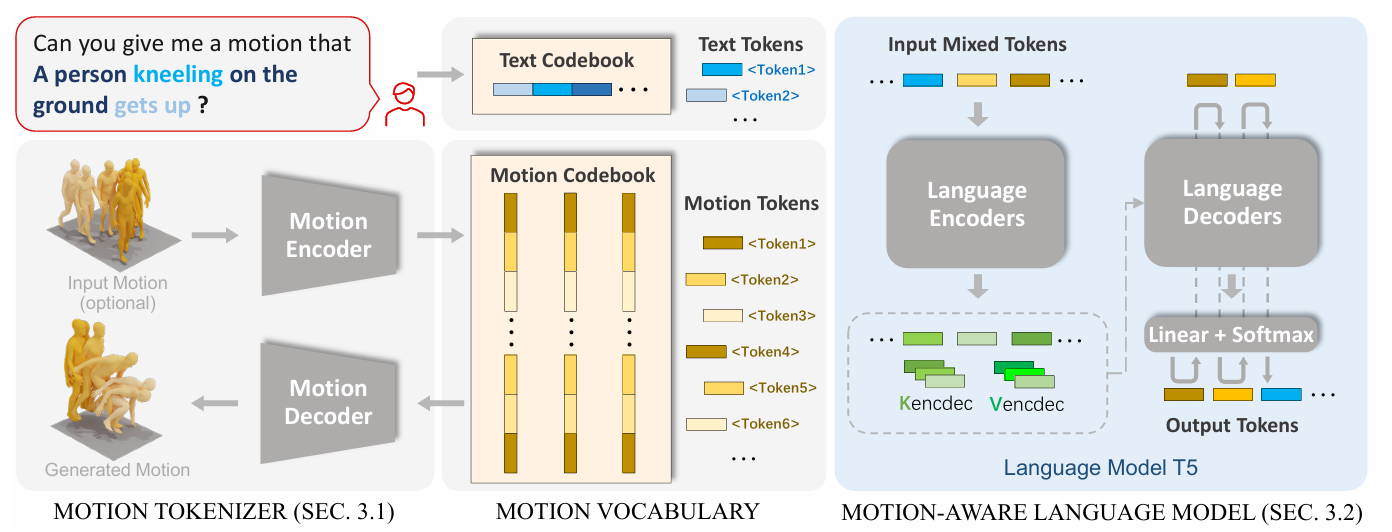
Figure 2
MotionGPT는 raw motion data를 discrete motion token으로 변환하는 motion tokenizer(Sec 3.1)를 포함하고, motion-aware 언어 모델이 motion token에 맞는 텍스트 설명을 통해 LLMs이 motion token을 이해할 수 있도록 학습한다(Sec 3.2).
- MotionGPT consists of a motion tokenizer responsible for converting raw motion data into discrete motion tokens (Sec. 3.1), as well as a motion-aware language model that learns to understand the motion tokens from large language pre-training models by corresponding textual descriptions (Sec. 3.2).
Motion과 관계된 task를 다루기 위해, MotionGPT의 학습 방식을 Motion tokenizer, motion-language pre-training, instruction tuning 3단계로 구성했다.
- To address motion-relevant tasks, we introduce a three-stage training scheme (Sec. 3.3) of MotionGPT for the training of motion tokenizer, motion-language pre-training, and instruction tuning.
Motion Tokenizer
| Frame의 길이 | $M$ |
|---|---|
| temporal downsampling rate on motion length | |
| 모션 길이에 대한 시간 축 다운샘플링 비율 | $l$ |
| motion token의 길이 | $L=M/l$ |
| $M$ frame의 motion | $m^{1:M}={x^i}^M_{i=1}$ |
| $L$길이의 motion token | $z^{1:L}={z^i}^L_{i=1}$ |
| $N$길이의 문장 | $w^{1:N}$ |
$M$ frame의 motion $m^{1:M}$
encoder $\mathcal{E}$
$z^{1:L}=\mathcal{E}(m^{1:M})$
decoder $\mathcal{D}$
$m^{1:M}=\mathcal{D}(z^{1:L})$
MotionGPT로부터 생성되는 $L$ 길이의 token $\hat{x}^{1:L} = {\hat{x}^i}^L_{i=1}$
Given motion: $\hat{m}^{1:M}$
Result: $\hat{x}^{1:L}_t$(text)
Given sentence: $\hat{w}^{1:L}$
Result: $\hat{x}^{1:L}_m$(motion)
- We first propose the motion tokenizer consisting of a motion encoder $\mathcal{E}$ and a motion decoder $\mathcal{D}$, to encode a $M$ frame motion $m^{1:M} = {x^i}^M_{i=1}$ into $L$ motion tokens $z^{1:L} = {z^i}^L_{i=1}$, $L = M/l$, and decode $z^{1:L}$ back into the motion $\hat{m}^{1:M} = \mathcal{D}(z^{1:L}) = \mathcal{D}(\mathcal{E}(m^{1:M}))$, where $l$ denotes the temporal downsampling rate on motion length. Then, given an $N$ length sentence $w^{1:N} = {w^i}^N_{i=1}$ describing a motion-related question or demand, MotionGPT aims to generate its answer as $L$ length tokens $\hat{x}^{1:L} = {\hat{x}^i}^L_{i=1}$. It could be the human motion tokens $\hat{x}^{1:L}_m$ or the text tokens $\hat{x}^{1:L}_t$ , which results in a motion $\hat{m}^{1:M}$ or a sentence $\hat{w}^{1:L}$ like a description of the given motion.
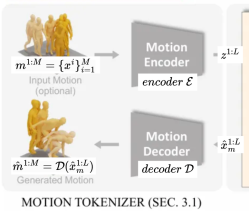
3.1 Motion Tokenizer
Motion을 discrete token으로 표현하기 위해, Vector Quantized Variational Autoencoders 구조를 사용해 3D human motion tokenizer $\mathcal{V}$를 pre-train한다.
motion tokenizer는 인코더 $\mathcal{E}$와 디코더 $\mathcal{D}$로 구성되어있다.
- To represent motion in discrete tokens, we pre-train a 3D human motion tokenizer V based on the Vector Quantized Variational Autoencoders (VQ-VAE) architecture
인코더 $\mathcal{E}$는 높은 정보 밀도를 가진 discrete motion token을 생성하고, 디코더$\mathcal{D}$는 discrete motion token으로부터 motion sequences $\hat{m}^{1:M}$을 재구현(디코딩)한다.
이러한 과정을 통해 motion을 언어로 효과적으로 표현할 수 있게 하며, 다양한 motion과 관련된 작업을 위한 motion과 언어의 통합을 가능하게 한다.
- The encoder generates discrete motion tokens with high informative density, while the decoder is able to reconstruct the motion tokens into motion sequences $\hat{m}^{1:M}$.
- This approach enables us to efficiently represent motion as a language, facilitating the integration of motion and language for various motion-related tasks.
특히, motion 인코더 $\mathcal{E}$는 1D convolution을 제공된 fram-wise motion feature $m^{1:M}$에 시간 축(time dimension)으로 적용해, latent vector $\hat{z}^{1:L}=\mathcal{E}(m^{1:M})$를 얻는다.
- Specifically, the motion encoder E first applies 1D convolutions to given frame-wise motion features $m^{1:M}$ along the time dimension, to obtain latent vectors $\hat{z}^{1:L}=\mathcal{E}(m^{1:M})$.
다음, $\hat{z}$를 discrete quantization을 통해 codebook entry $z$로 변환한다.
- Next, we transform $\hat{z}$ into a collection of codebook entries $z$ through discrete quantization.
학습 가능한 코드북 $Z ={z^i}^K_{i=1}\sub\mathbb{R}^d$ 는 $d$차원의 $K$개의 latent embedding vector로 이루어져 있다. 양자화 과정 $Q(\cdot)$은 각 row vector $b$를 코드북 $Z$에 있는 가장 가까운 엔트리 $b_k$로 치환한다.
- The learnable codebook $Z ={z^i}^K_{i=1}\sub\mathbb{R}^d$ consists of $K$ latent embedding vectors, each of dimension $d$. The process of quantization $Q(\cdot)$ replaces each row vector $b$ with its nearest codebook entry $b_k$ in $Z$, written as $z_i = Q(\hat{z}^i):= \argmin_{z_k\in Z}|\hat{z}_i-z_k|_2$
양자화 이후, motion 디코더$\mathcal{D}$ 는 $z^{1:L}={z^i}^L_{i=1}$을 $M$프레임의 motion $\hat{m}^{1:M}$인 raw motion space로 project(사영)시킨다.
- After quantization, the motion decoder $\mathcal{D}$ project $z^{1:L}={z^i}^L_{i=1}$ back to raw motion space as the motion $\hat{m}^{1:M}$ with M frames.
이 motion tokenizer를 학습하기 위해, [11, 57] 논문을 따라, 학습을 위한 3개의 구분된 loss functions을 구성하고, motion tokenizer$\mathcal{L}_\mathcal{V}$를 최적화한다. $\mathcal{L}_\mathcal{V} = \mathcal{L}_r+\mathcal{L}_e+\mathcal{L}_c$ 이며, reconstruction loss $\mathcal{L}_r$, embedding loss $\mathcal{L}_e$, commitment loss $\mathcal{L}_c$가 포함된다.
- To train this motion tokenizer, we follow [11, 57] to utilize three distinct loss functions for training and optimizing the motion tokenizer: $\mathcal{L}_\mathcal{V} = \mathcal{L}_r+\mathcal{L}_e+\mathcal{L}_c$, where the reconstruction loss $\mathcal{L}_r$, the embedding loss $\mathcal{L}_e$, and the commitment loss $\mathcal{L}_c$.
생성된 motion의 수준을 높이기 위해, [57]논문을 따라 L1 smooth loss과 $\mathcal{L}_r$에서 velocity regularization을 구성하고, exponential moving average(EMA)와 codebook reset techniques들을 사용해 훈련하는 동안 codebook의 utilization을 강화하고자 했다.
- To further improve the generated motion quality, we follow [57] to utilize $\mathrm{L1}$ smooth loss and velocity regularization in the reconstruction loss, as well as exponential moving average ($\mathrm{EMA}$) and codebook reset techniques [37] 4 to enhance codebook utilization during training.
## 3.1 Motion Tokenizer 정리 **VQ-VAE 구조** 사용 인코더, 양자화, 디코더 총 3가지 단계로 나눌 수 있음. 인코더: motion -> motion token 양자화: motion token 양자화 디코더: 생성된 motion token -> motion
3.2 Motion-aware Language Model
만든 motion tokenizer를 적용하여, human motion $m^{1:M}$은 언어 모델의 vocabulary embedding과 유사한 형태로 표현된 motion token sequence $z^{1:L}$로 매핑된다. 이를 통해 joint representation을 가질 수 있다.
- Employing this motion tokenizer, a human motion $m^{1:M}$ can be mapped to a sequence of motion tokens $z^{1:L}$, allowing for joint representation with similar vocabulary embedding in language models.
언어와 motion을 하나의 vocabulary로 합쳐, motion과 언어를 공통되게 학습한다.
- By combining them in the unified vocabulary, we then learn motion and language jointly.
motion token$z^{1:L}$을 인덱스 시퀀스 $s^{1:L} = {s^i}^L_{i=1}$로 표현하며, 여기서 $s^i$는 모션 토큰의 인덱스 $i$에 해당한다.
- We first represent motion tokens $z^{1:L}$ as a sequence of indices $s^{1:L} = {s^i}^L_{i=1}$, where $s^i$ corresponds to the index number of motion tokens $z^{1:L}$.
반면, T5와 같은 기존 언어 모델은 text를 WordPiece token으로 인코딩했다.
T5는 $K_t$개의 word pieces로 vocabulary를 구성했고, 여러 언어 데이터셋을 혼합하여 SentencePiece 모델을 학습했다.
- On the other hand, previous language models, such as T5 [36], encode text as WordPiece tokens. They utilized a vocabulary of Kt word pieces and trained the SentencePiece [18] model on a mixture of language datasets.
이전 text-to-motion이나 motion-to-text의 접근들은 text와 motion에 서로 다른 모듈을 적용했다. 하지만 MotionGPT는 text와 human motion을 함께 다루는 모델에 초점을 맞추고 있다.
- Most previous text-to-motion [11, 52, 57] or motion-to-text [11] approaches employ different modules to handle text and motion individually, while we aim to model text and human motion together and in the same way.
이를 달성하기 위해, 기존의
원본 text vocabulary $V_t={\mathcal{v}^i_t}^{K_t}{i=1}$와 motion vocabulary $V_m = {\mathcal{v}^i_m}^{K_m}{i=1}$을 결합한다. 이때, $V_m$은 MotionGPT의 motion codebook $Z$의 순서를 유지한다.
- To achieve this, we combine the original text vocabulary $V_t={\mathcal{v}^i_t}^{K_t}{i=1}$ with motion vocabulary $V_m = {\mathcal{v}^i_m}^{K_m}{i=1}$, which is order-preserving to our motion codebook $Z$.
더 나아가, $V_m$은 모션의 시작과 끝을 나타내는 </som>과 </eom>과 같이, boundary indicators와 같은 여러개의 special tokens을 포함하고 있다.
- Moreover, $V_m$ includes several special tokens like boundary indicators, for example,
</som>and</eom>as the start and end of the motion.
최종적으로, 일반적인 format으로 다양한 motion 관련 task를 표현하는 통합된 text-motion vocabulary $V={V_t, V_m}$를 적용했다.
이를 통해 MotionGPT는 하나의 모델로 유연한 representation과 motion과 관련된 outputs를 생성한다.
- Thus, we employ a new unified text-motion vocabulary V = {Vt,Vm}, and can formulate diverse motion-related tasks in a general format, where both input "words" and output "words" are from the same V .
- Therefore, our MotionGPT allows for the flexible representation and generation of diverse motion-related outputs within a single model.
Conditioned generation task를 다루기 위해, [38]논문에서 제안된 트랜스포머 기반 모델 구조를 채택했으며, 이 모델은 input sequences와 output을 효과적으로 매핑한다.
- To address the conditioned generation task, we employ a transformer-based model based on the architecture proposed in [38], which effectively maps the input sequences to the output.
Input 소스는 토큰 시퀀스로 구성되어있다. $V$이므로, 모션과 텍스트가 통합되어있다.
$X_s = {{x_s}^i}^N_{i=1}$, $x_s \in V$, $N$: Input 길이
- Our source input consists of a sequence of tokens $X_s = {{x_s}^i}^N_{i=1}$, where $x_s \in V$ and $N$ represents the input length.
Target output도 토큰 시퀀스이고, 역시 $V$이므로 모션과 텍스트가 통합된 토큰이다.
$X_t = {{x_t}^i}^L_{i=1}$, $x_t \in V$, $L$: Input 길이
- Similarly, the target output is $X_t = {{x_t}^i}^L_{i=1}$, where $x_t \in V$ and $L$ denotes the output length.
Autoregressive 측면에서, source token이 transformer encoder로 피딩되고, 이어지는 decoder가 각 step마다 가능성 있는 다음 토큰에 대한 확률 분포를 예측한다.
- the source tokens are fed into the transformer encoder, and the subsequent decoder predicts the probability distribution of the potential next token at each step
$p_{\theta}(x_t \mid x_s) = \prod_i p_{\theta} \left( {x_t}^i \mid {x_t}^{<i}, x_s \right)$
in an autoregressive manner.
그러므로, training process에서 데이터 분포의 log-likelihoood를 최대화하는 것이 목적이다.
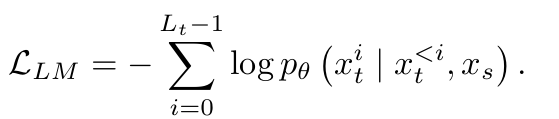
이 목적함수를 최적화하기 위해, MotionGPT는 데이터 분포로부터 내재된 패턴과 관계를 찾아내고, target “words”에 대해 정확하고 의미있는 생성을 유도한다.
- By optimizing this objective, MotionGPT learns to capture the underlying patterns and relationships from the data distribution, facilitating the accurate and meaningful generation of the target "words".
이 추론 과정에서, target token들은 end token이 나올 때까지 재귀적으로 예측된 분포로부터 sample된다.
- During the inference process, the target tokens are sampled recursively from the predicted distribution $p_{\theta} \left( {\hat{x}_t}^i \mid {\hat{x}_t}^{<i}, x_s \right)$
until the end token (i.e., ).
이런 sampling 전략으로 target sequence를 step-by-step으로 생성할 수 있게 된다.
target sequence의 토큰들은 이전에 생성된 토큰들과 제공된 source input으로부터 확률적으로 결정된다.
- This sampling strategy enables the generation of the target sequence in a step-by-step manner, where each token is probabilistically determined based on the previously generated tokens and the given source input.
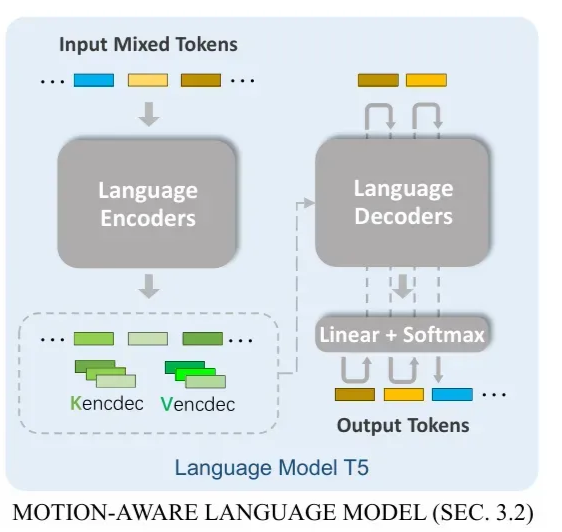
## 3.2 Motion-aware Language Model 정리
Conditioned generation task를 다루기 위해 [38]에서 제안된 **트랜스포머 기반 모델 구조 채택**
이유: **input sequences와 output을 효과적으로 매핑**할 수 있기 때문
motion tokenizer를 적용해 human motion을 motion token sequence로 매핑, codebook Z 사용
기존 text Vocabulary와 motion Vocabulary를 결합해 하나의 Vocabulary로 통합
Source token이 transformer encoder로 feed되고, 이어지는 decoder가
다음 토큰에 대한 확률 분포 예측
- 이때, encoder와 decoder는 motion tokenizer의 encoder, decoder가 아닌 트랜스포머 기반
모델 구조에서 사용되는 encoder, decoder로 보여집니다.
[38] Exploring the limits of transfer learning with a unified text-to-text transformer.추가 발견 사항 22:34
- scholar.google.com을 통해 찾은 paper과, github에 게재된 paper와 조금 다름을 확인
- 다른 논문에서부터 이전 연구인 T2M-GPT와 차이점 발견
Motion만 생성하는 T2M-GPT는 VQ-VAE와 Transformer를 기반으로 한 생성 프레임워크다.
- T2M-GPT investigates a generative framework based on VQ-VAE and Transformer for motion generation only
CLIP을 활용해 text embedding을 추출하여 motion generation condition으로 사용함으로써 언어 정보 통합. MDM, MLD, MotionDiffuse와 같은 대부분 이전 연구와 유사함.
- They incorporate language information by leveraging CLIP [35] to extract text embedding as motion generation conditions, which is similar to most previous work, such as MDM [48], MLD [54], and MotionDiffuse [60].
3.3 Training Strategy
T5가 text vocabulary $V_t$인 언어 데이터만 보였기 때문에, motion과 언어를 이 language model이 학습된 motion vocabulary $V_m$인 human motion concepts의 이해를 할 수 있도록 연결한다.
- Since T5s have only been exposed to language data, represented within a text vocabulary $V_t$, we thus bridge motion and language and enable this language model to comprehend human motion concepts, by learning the motion vocabulary $V_m$.
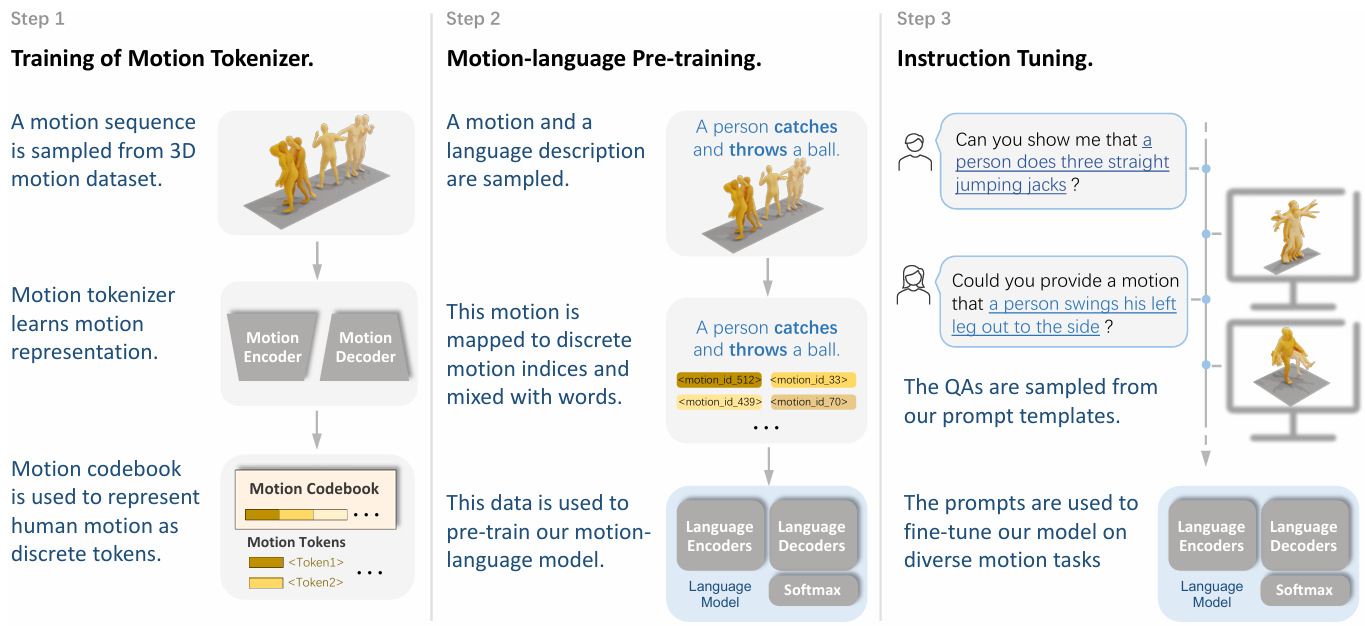
Figure 3
Figure 3에 나타나는 것처럼, training scheme은 3가지 단계로 구성되어있다.
(1) Motion tokenizer 학습 - human motion을 discrete tokens으로 표현하기 위한 motion codebook을 학습하는데 집중한다
- Training of motion tokenizer, which focuses on learning the motion codebook to represent human motion as discrete tokens.
(2) Motion-language pre-training stage는 비지도/지도 objectives(목적 함수?)를 통해 motion과 language의 관계를 학습한다.
- (2) Motion-language pre-training stage, which includes unsupervised and supervised objectives to learn the relationship between motion and language.
(3) Instruction tuning stage에서 다양한 motion과 관련된 작업에 대해 prompt 기반 instruction으로 모델을 fine-tune한다.
- Instruction tuning stage, which tunes the model based on prompt-based instructions for different motion-relevant tasks.
Training of Motion Tokenizer
Equation 3.1에 정의된 목적 함수($\mathcal{L}_\mathcal{V} = \mathcal{L}_r+\mathcal{L}_e+\mathcal{L}_c$)를 사용해 motion tokenizer를 학습한다.
- We first learn the motion tokenizer using the objective defined in Equation 3.1
이 학습 프로세스는 어떤 human motion sequence $\hat{x}^{1:L}$도 motion token의 시퀀스로 표현할 수 있도록 하여, 매끄러운 textual 정보와 통합을 가능케 한다.
- This training process allows any human motion sequence $\hat{x}^{1:L}$ to be represented as a sequence of motion tokens, enabling seamless integration with textual information.
한번 최적화 되고나면, motion tokenizer는 후속 pipeline stage동안 변하지 않는다.
- Once optimized, the motion tokenizer remains unchanged throughout the subsequent stages of the pipeline.
Motion-language Pre-training Stage
T5모델은 자연어 데이터셋으로 학습되고, instruction 기반 phrasing으로 fine-tune 되었습니다.
- The T5 models [38, 5] are trained and fine-tuned on natural language datasets with instruction-based phrasing.
MotionGPT는 이 모델(T5)을 언어와 motion데이터를 결합해, 비지도/지도 방식으로 이어서 pre-train했다.
- We continue to pre-train this model using a mixture of language and motions data in both unsupervised and supervised manners
1) downstream task를 일반화 하기 위해, [38]을 따라 목적 함수를 디자인했다.
그 디자인은 input tokens $X_s$의 특정 퍼센트(15%)의 토큰들을 무작위로 특별한 sentinel token으로 교체한다.
- 1) To generalize to various downstream tasks like [7, 37, 38, 28], we follow [38] to design an objective, where a certain percentage (15%) of tokens in the input tokens $X_s$ are randomly replaced with a special sentinel token.
- [38]: Exploring the limits of transfer learning with a unified text-to-text transformer.
그리고, 이에 해당하는 target sequence는 input sequence에서 sentinel token으로 대체된 부분을 추출하여 구성하며, target sequence의 끝을 나타내는 추가 sentinel token을 포함한다.
- On the other side, the corresponding target sequence is constructed by extracting the dropped-out spans of tokens, delimited by the same sentinel tokens used in the input sequence, along with an additional sentinel token to indicate the end of the target sequence.


이를 통해 motion과 language의 관계를 text-motion dataset 쌍으로 지도 학습으로 배웠다.
- 2) We then learn the motion-language relation by the supervision of paired text-motion datasets [11, 33].
저자는 MotionGPT를 입력(human motion 또는 text description)에 관계없이, motion-language 번역으로 지도 학습을 진행했다.
- We train MotionGPT on the supervised motion-language translation, where the input is either a human motion or a text description.
비지도/지도 학습 프로세스를 마친 , model이 text와 motion의 관계에 대한 이해를 장착할 수 있도록 목표했다.
- After unsupervised and supervised training processes, we aim to equip our model with the understanding of text and motion relationships.
Instruction Tuning Stage
다중 작업을 다루는 text-motion 데이터셋을 구성했다. HumanML3D나 KIT와 같은 데이터셋을 기반으로 instruction을 구성했다.
- We construct a multi-task text-motion dataset by formulating it as instructions, building upon the foundation of existing text-to-motion datasets such as HumanML3D [11] and KIT [33].
특히, 15개의 핵심 motion task를 정의했다. 예를 들어 text로 motion 생성 / motion captioning / motion prediction 등이 있다.
- Specifically, we define 15 core motion tasks, such as motion generation with text, motion captioning, motion prediction, and others.
각 작업별로 고유한 instruction prompt를 가진 여러 개의 insturction template를 구성해, 수천개의 서로 다른 작업을 만들었다.
- For each task, we compose dozens of different instruction templates, resulting in more than one thousand different tasks, each having a unique instruction prompt.
예시
Motion Generation task의 instruction prompt
“Can you generate a motion sequence that depicts ‘a person emulates the motions of a waltz dance’?”
Motion captioning task의 instruction prompt
"Provide an accurate caption describing the motion of ”
Sec 4.3에서 insturction tuning의 효용을 입증했고, 이를 통해 다양한 작업에서 성능 개선과 처음 접하는 작업 또는 prompt에 대한 모델

성능도 향상할 수 있었다.
- We have demonstrated the efficacy of instruction tuning in Sec. 4.3, which leads to improvement across various tasks and enhances the model performance for unseen tasks or prompts.
## Tranining Strategy 정리
1. Motion Tokenizer 학습
한번 최적화 된 이후, 후속 pipeline stage 진행 시 변하지 않음.
2. Motion-language Pre-training Stage
언어모델 T5의 train 방식을 사용해 text와 motion의 관계를 학습
3. Instruction Tuning Stage
각 작업별로 고유한 여러 개의 instruction template를 구성해,
수천개의 서로 다른 작업을 만들어 fine tune 진행FID: Frechet Inception Distance
- 실제 motion과 생성된 motion 분포의 거리를 측정, 낮을수록 good
R TOP: motion-retrieval precision (R Precision)
- 텍스트 설명과 모션의 매칭 정확도 평가. Text matching.
DIV: Generation diversity
- 모션에서 추출된 분산을 계산해, 모션간의 차이를 평가.
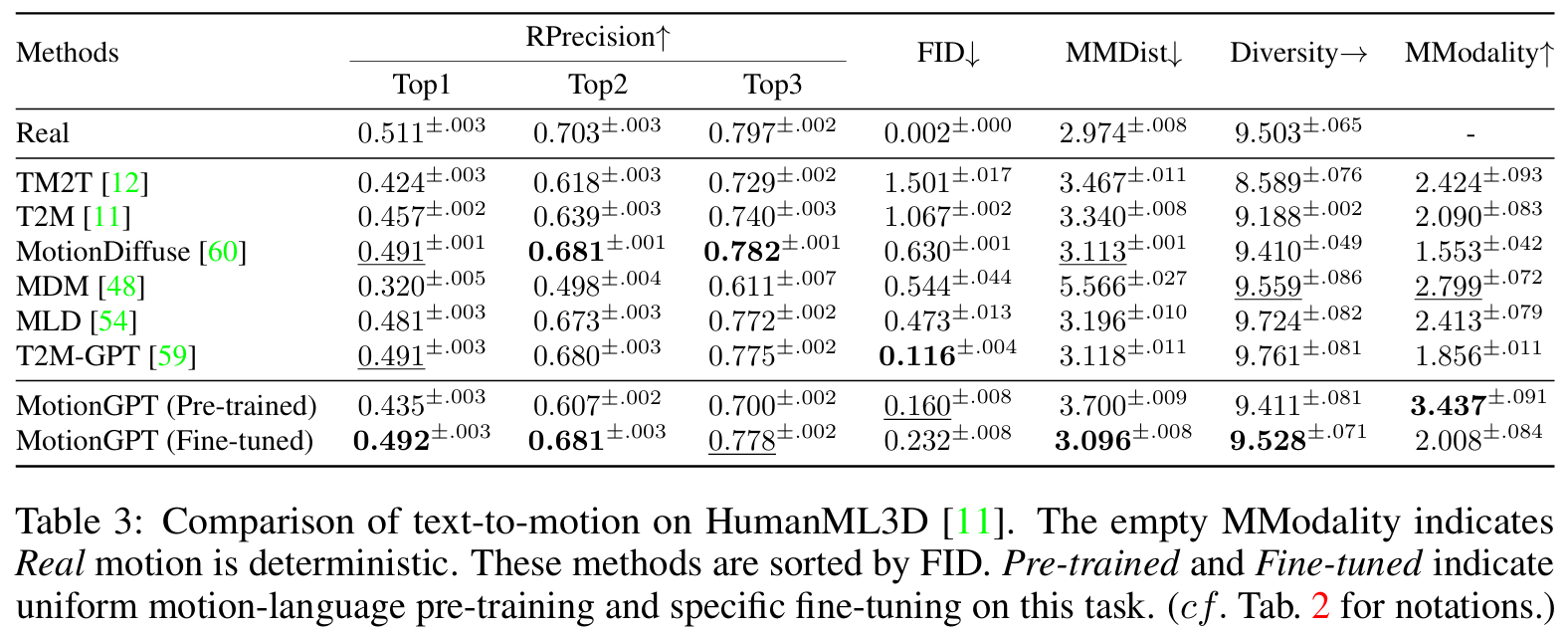
MMDist: Multi-modal Distance
- motions과 texts의 거리를 측정
MModality: MultiModality
- motion의 같은 text description으로 생성된 motion의 diversity 측정


