Hierarchical Layer: base layer << 와 같이 파란색으로 표현
초록 (Abstract)
새로운 text-driven 3D 사람 모션 생성을 위한 masked modeling frame-work인 MoMask를 소개한다.
MoMask는 사람 모션을 high-fidelity detail을 표현하는 multi-layer discrete motion 토큰으로 표현하기 위해 계층적 양자화 방식(Hierarchical quantization scheme)을 사용한다.
Vector Quantization으로 부터 얻어진 모션 토큰 시퀀스는 base layer부터 시작해서 순차적으로 residual 토큰을 만들고, hierarchy의 subsequent layer을 통해 저장된다.
이후, 두 개의 bidirectional transformers를 통과한다.
| Masked Transformer | Residual Transformer |
훈련 stage
- Masked Transformer는 text input 조건에 맞는 base-layer 모션 토큰에 대해서 random하게 mask된 모션 토큰을 예측하도록 설계되었다.
생성 stage
- empty sequence로 부터, Maksed Transformer가 반복적(iteratively)으로 missing 토큰을 채운다.
이어서, Residual Transformer는 현재 레이어의 result를 기준으로 다음 레이어의 토큰을 점진적으로 예측하는 것을 학습한다.
여러 실험 결과는 MoMask가 text-to-motion 생성 과제에서 State-of-art(SOTA)라는 것을 보여줍니다.
- HumanML3D / FID 0.045
- KIT-ML / FID 0.228
또한, MoMask는 fine-tuning 없이 text-guided temporal inpainting과 같은 작업에 적용될 수 있다.
# Abstract
MoMask는 크게 3가지 구조로 구성
1. RVQ-VAE
VQ-VAE에 계층적 양자화 방식을 적용해, 총 V개의 hierarchical layer로 구성
총 V개의 codebook이 생성됨
2. Masked Transformer
BERT를 기반으로 BERT의 학습 방식을 사용
훈련
- random하게 masking을 진행하고, masking된 부분을 예측하는 학습을 진행
생성
- empty sequence를 제공하고, empty sequence로 부터 토큰 생성
3. Residual Transformer
현재 hierarchical layer의 result를 기준으로, 다음 hierarchical layer의 토큰을 점진적으로 예측소개 (Introduction)
Textual 설명으로 부터 3D 사람 모션을 생성하는 것, 즉 text-to-motion 생성은 비디오 게임, 메타버스, VR&AR에서 중요한 역할을 할 수 있는 비교적 새로운 과제다.
그 중, 사람 모션을 모델링하기 위해 generative transformer를 사용하는 것이 become popular.
이 pipeline은 다음과 같다.
- 모션이 VQ(Vector Quantization)를 통해 이산 토큰(discrete tokens)으로 변모
- Autoregressive model에 입력(fed)되어 단방향 순서(unidirectional order)으로 모션 시퀀스 생성
인상적인 결과를 가져다 주었지만, 두 가지 본질적인 한계가 있다.
- VQ process는 필연적으로 근사 오차(approximation error)가 발생하고, 모션 생성 퀄리티를 제한
- 단방향 디코딩 방식은 생성 모델의 표현력을 불필요하게 제한
- 매 step에서, motion content가 전체 문맥이 아니라 이전의 문맥(preceding context)만 고려해 생성되는 문제
- 생성 과정에서 축적되는 오류
다른 연구에서는 이산 디퓨전 모델(Discrete Diffusion Models)으로 번거로운 이산 디퓨전 과정에 의존해 모션 토큰을 양방향으로 디코딩했지만, 모션 시퀀스 생성을 위해 수백 번의 반복이 필요
MoMask, high-quality + 효율적인 text-to-motion 생성을 위한 framework
- Residual Vector Quantization(RVQ) 기술과 recent generative masked transformers
MoMask 구성 요소
- RVQ-VAE
- 3D 모션과 이에 해당하는 이산 모션 토큰(discrete motion token) 시퀀스 사이의 정밀한 매핑을 위함
- 일반적으로 latent code를 single pass로 양자화하는 이전의 모션 VQ tokenizer와 달리, 계층적인 RVQ(hierarchical RVQ)는 residual quantization의 반복을 통해 quantization error를 점진적으로 줄인다.
- 결국 multi-layer motion token이 형성
- base layer는 기본적인 모션 양자화를 수행
- 나머지 layer는 계층적으로 residual coding error를 잡아낸다.
- Masked Transformer (M-Transformer)
- base VQ layer를 위한 모션 토큰 생성
- 학습
- BERT 기반
- textual input을 조건으로 임의로 마스킹된 토큰을 예측하도록 학습
- Masking 비율은 [0, 1] 범위의 변수로 조정
- 생성
- 모든 토큰이 Masking됨
- M-Transformer는 완성된 모션 토큰 시퀀스를 생성 (적은 iteration으로)
- 모든 masked token은 동시에 predict
- Highest confidence인 token은 유지
- 다른 token은 다시 masked된 후, 다음 iteration에서 다시 예측
- 최종적으로 base-layer token 생성
- Residual Transformer (R-Transformer)
- 나머지 residual layer를 위한 모션 토큰 생성
- 현재 layer의 토큰 시퀀스를 기반으로 점진적으로 subsequent layer의 residual 토큰 예측
결과적으로 모션의 길이와 관계 없이 약 15번의 iteration으로 전체 레이어의 모션 토큰이 생성됨
주요 기여점
- MoMask는 text-to-motion 생성 문제에서 최초로 generative masked modeling framework 제안
- hierarchical quantization generative model
- 정밀한 residual quantization을 위한 전용 매커니즘
- Base token 생성
- Residual token 예측
- hierarchical quantization generative model
- MoMask 파이프라인은 정확하고 효율적인 text-to-motion 생성을 가능하게 함
- text-to-motion 생성 task에서 New SOTA performance 달성
- MoMask는 텍스트 기반 motion inpainting과 같은 작업에도 원활이 적용
# Introduction
Abstract에서 조금 더 구체화된 설명
결국 MoMask는 크게 3가지 구조로 구성되어 있다.
1. RVQ-VAE
계층적 구조를 통해 quantization error를 최소화 하고자 함
2. M-Transformer
BERT 기반 Transformer
iteration을 돌며 전체 시퀀스 길이의 모션을 생성
신뢰도가 높은 토큰은 유지, 나머지 토큰은 다시 masking을 통해 다시 예측
3. R-Transformer
Base-layer의 토큰(M-Transformer로 부터 생성)부터 subsequent layer의 토큰을 모두 예측
최종적으로 전체 레이어의 모션 토큰 생성(Base layer부터 마지막 layer까지)관련 연구(Related Work)
Human Motion Generation
다음과 같은 domain을 조건으로 모션 생성
- Motion prefix
- action class
- audio
- texts
초기 연구
- Stochastic model
- averaged and blurry 모션
| GAN | action-conditioned 모션 생성 |
| T2M | Tempral VAE 확장 텍스트와 모션 사이의 probabilistic 매핑 학습 |
| TEMOS | Transformer VAE 활용 자연어와 모션 사이의 Joint Variational Space 최적화 |
| TEACH | TEMOS를 긴 모션 구성으로 확장 |
| MotionCLIP, ohMG | 비지도학습 방식으로 모델링 대규모 사전학습 모델 CLIP 사용 |
| Diffusion Method | Network는 모션 시퀀스를 점진적으로 denoise하도록 학습 Diffusion process로 supervised |
| Autoregressive Model | 먼저 모션을 vector quantization으로 양자화 언어 모델처럼 강력한 Transformer로 모델링 |
Generative Masked Modeling
| BERT | • 언어 과제에서 masked modeling 제안 ◦ 단어 토큰이 고정된 비율로 무작위로 마스킹 되고, bidirectional transformer가 마스킹된 토큰을 예측하도록 학습 • 뛰어난 text encoder지만, 새로운 sample을 생성할 수는 없음 • 이를 해결하기 위해 스케줄링 함수에 의해 제어되는 가변하고 추적가능한 비율로 토큰을 마스킹하는 기법 제안 • 스케줄에 따른 마스킹을 통해 새로운 샘플 반복적으로 생성 |
| MAGE | • masked generative encoder로 표현 학습(representation learning)과 이미지 생성(image synthesis)을 통합 |
| Muse | • MAGE의 패러다임을 text-to-image 생성 및 편집으로 확장 |
| Magvit | • multi-task 비디오 생성을 위한 다목적 마스킹 기법 제안 |
Deep Motion Quantization and RVQ
| [Deep motifs and motion signatures] | • 의미론적으로 의미있는 이산 모션 단어를 삼중 대조 학습(triplet contrastive learning)으로 학습 |
|---|---|
| TM2T | • Vector Quantized-VAE 처음으로 적용 • 사람 모션과 이산 토큰(discrete token)의 상호 매핑 학습 • autoencoding latent code는 codebook에서 선택된 항목으로 대체 |
| T2M-GPT | • EMA와 code reset technique로 TM2T 강화 |
그러나, 양자화 과정은 필연적으로 오류 발생
- 최적의 모션 재구성이 어려움
Neural Network 압축과 오디오 양자화에 사용된 Residual Quantization기법 적용
- 반복적으로 Vector와 residual을 양자화
- 고정밀 모션 이산화(motion discretization) 가능
# Related Work
BERT는 강력한 encoder지만, 생성 능력이 떨어짐
→ **스케줄링 함수에 의해 제어되는 마스킹 기법**으로 극복하고자 함
양자화 과정은 **필연적**으로 error 발생
→ Residual Quantization 기법을 적용해 극복하고자 함Approach

목표
- 길이가 N이고, 텍스트 c로 가이드된 3D 사람 포즈 시퀀스 $m_{1:N}$ 생성
$m_i \in \mathbb{R}^D$, $D$는 pose feature의 차원 - 3개의 주된 구성요소
- Residual-based quantizer
- 모션 시퀀스를 multi-layer discrete token으로 토큰화
- Masked Transformer
- Base layer의 모션 토큰 생성
- Residual Transformer
- subsequent residual layer의 토큰 예측
Training: Motion Residual VQ-VAE
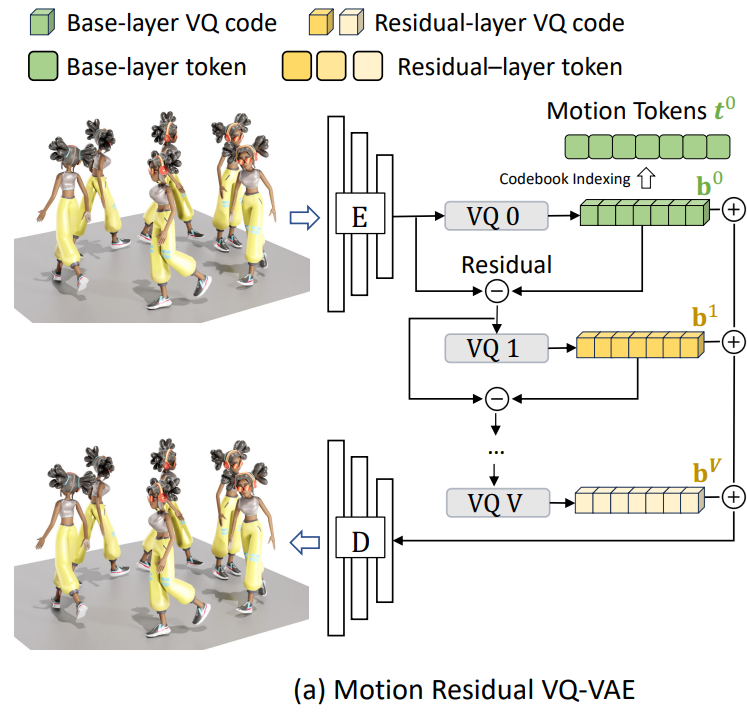
기존의 VQ-VAEs는 모션 시퀀스를 하나의 이산 모션 토큰 튜플(one tuple of discrete motion tokens)로 변환함.
기존 VQ-VAEs의 구체적인 과정
- 모션 시퀀스 $ \mathbf{m}_{1:N} \in \mathbb{R}^{N\times D} $ 는 $1$$\text{D}$ convolutional encoder $ \text{E} $를 사용해 다운샘플링 비율 $ n/N $과 latent 차원 $ d $를 가진 latent vector 시퀀스 $\tilde{\mathbf{b}}_{1:n}\in\mathbb{R}^{N\times D} $로 먼저 인코딩
- 각 vector는 사전 설정된 코드북 $ \mathcal{C} = {c_k}^K_{k=1}\subset\mathbb{R}^d $의 가장 가까운 code entry로 대체되며, 이 과정을 양자화(quantization) $ \text{Q}(\cdot) $라고 한다.
- 이렇게 양자화된 code 시퀀스 $ \text{b}_{1:n}=\text{Q}(\tilde{\mathbf{b}}_{1:n})\in\mathbb{R}^{n\times d} $ 는
모션 공간으로 재투영(projected back)됨. $ \hat{\mathbf{m}}=\text{D}(\mathbf{b}) $ - 최종적으로, 선택된 codebook 항목의 인덱스(모션 토큰)는 입력 모션의 이산 표현(discrete representation) 대체재로 사용됨
- 양자화 작업 $\text{Q}(\cdot)$은 효과적이지만, 필연적으로 정보 손실을 가져옴
- 재구성(reconstruction) 품질에 한계가 있음
정보 손실을 해결하기 위한 Residual Quantization(RQ)
- latent 시퀀스 $\tilde{\mathbf{b}}$를 $V+1$개의 quantization layer로 $V+1$개의 순서있는 code 시퀀스로 표현
- $\text{RQ}(\tilde{\mathbf{b}}{1:n})=[\mathbf{b}^v{1:n}]^V_{v=0}$으로 정의
$\mathbf{b}^v_{1:n}\in\mathbb{R}^{n\times d}$는 $v$-$\text{th}$ quantization layer의 code 시퀀스를 의미한다.
- $\text{RQ}(\tilde{\mathbf{b}}{1:n})=[\mathbf{b}^v{1:n}]^V_{v=0}$으로 정의
- $0$-$\text{th}$ residual $\mathbf{r}^0=\tilde{\mathbf{b}}$ 에서 시작해, $\text{RQ}$는 재귀적으로 활용해 residual $\mathbf{r}^v$의 근사치인 $\mathbf{b}^v$를 계산하고, 다음 residual $\mathbf{r}^{v+1}$을 다음과 같이 계산한다.
$\mathbf{b}^v=\text{Q}(\mathbf{r}^v),$ $\mathbf{r}^{v+1}=\mathbf{r}^v-\mathbf{b}^v,$ $\text{for }v=0, ..., V$ - $\text{RQ}$이후, latent 시퀀스 $\tilde{\mathbf{b}}$의 최종 근사치는 모든 양자화된 시퀀스의 합 $\sum^V_{v=0}\mathbf{b}^v$로 이뤄짐
- 이후 decoder $\text{D}$에 입력되어 모션 재구성
$\hat{\mathbf{m}}=\text{D}(\sum^V_{v=0}\mathbf{b}^v)$
전반적으로, residual VQ-VAE는 각 quantization layer에서 모션 재구성 손실(motion reconstruction loss)과 latent 임베딩 손실(latent embedding loss) 결합한 손실을 통해 학습됩니다.
$\mathcal{L}{rvq} = |\mathbf{m} - \hat{\mathbf{m}}|{1} + \beta \sum\limits_{v=1}^V | \mathbf{r}^{v} - \text{sg}[\mathbf{b}^{v}] |_{2}^{2}$
$\text{sg}[\cdot]$: stop-gradient operation
$\beta$: 임베딩 제약(embedding constraint)의 가중치
이 framework는 straight-though gradient estimator로 최적화되고, EMA(Exponential Moving Average)와 codebook reset을 통해 codebook이 업데이트 됩니다.
Quantization Dropout
초기 quantization layer는 input motion을 최대한 많이 복원하는 것을 목표
이후 layer들은 잃어버린 세부 정보 추가
양자화 용량을 최대한 활용하기 위해, $quantization$ $dropout$전략 채택
- 무작위로 마지막 $0\sim V$ layer를 확률 $q\in[0,1]$로 비활성화
학습 이후, 각 모션 시퀀스 $\mathbf{m}$은 $V+1$개의 이산 모션 토큰 시퀀스 $T=[t^v_{1:n}]^V_{v=0}$로 표현
각 토큰 시퀀스 $t^v_{1:n}\in{1, ..., |\mathcal{C}^v|}^n$는 양자화된embedding vector $\mathbf{b}^v_{1:n}$의 ordered codebook의 인덱스이다.
$\mathbf{b}^v_i=\mathcal{C}^v_{t^v_i} ~ \text{for} ~ i\in[1,n]$
이 $V+1$시퀀스 중 첫 번째(base) 시퀀스는 가장 중요한 정보를 가지고 있고,
이후 레이어들의 영향은 점차 감소합니다.
RVQ-VAE
VQ-VAE의 필연적인 정보 손실을 보완
Residual Quantization 기법을 적용해 정보 손실 최소화
자세한 프로세스는 위에 1~5를 참고Training: Masked Transformer

Bidirectional masked transformer는 base-layer 모션 토큰 $t^0_{1:n}\in\mathbb{R}^n$을 모델링
- 무작위로 시퀀스 요소의 일부를 마스킹
- 토큰을 [MASK]토큰으로 대체
- 마스킹 후의 시퀀스를 $\tilde{t}^0$라 할 때, 목표는 마스킹된 토큰을 text $c$와 $\tilde{t}^0$를 사용해 예측
- text feature 추출을 위해 CLIP 사용
수학적으로, Masked Transformer $p_\theta$는 target prediction의 negative log-likelihood를 최소화하도록 최적화
$\mathcal{L}{\text{mask}} = \sum\limits{\tilde{t}^0_k = \text{[MASK]}} -\log p_{\theta} \left( t^0_k \mid \tilde{t}^0, \mathbf{c} \right).$
Mask Ratio Schedule
마스킹 비율을 조정하기 위해 cosine function $\gamma(\cdot)$를 채택
마스킹 비율은 다음과 같이 계산된다.
$\gamma(\tau) = \text{cos}(\frac{\pi\tau}{2})~\in~[0,1], ~\text{where}~~\tau~\in~[0,1],$ $\tau=0$은 모두 마스킹 됨을 의미
학습하는 동안, $\tau \sim \mathcal{U}(0,1)$(uniform 분포를 따르는) $\tau$는 무작위로 샘플링되며
$m=\lceil\gamma(\tau)\cdot n\rceil$개의 시퀀스 항목이 균일하게 선택되어 마스킹된다. $n$: 시퀀스 길이
Replacing and Remasking
Masked Transformer의 문맥적 추론(contextual reasoning)을 강화하기 위해, BERT pretraining에 사용된 remasking 전략 채택
어떤 토큰이 Masking 하기로 선택되었다면
- 80% 확률로 [MASK]토큰으로 교체된다
- 10% 확률로 random 토큰으로 교체된다
- 10% 확률로 교체되지 않는다.
Masked Transformer
Masked Transformer의 학습 방법과, 추론 방법에 대해 이야기.
자세한 방법은 위 글을 확인
Mask Ratio Schedule을 통해 마스킹 비율을 조정하고
Replacing and Remasking으로 문맥적 추론 강화Training: Residual Transformer

Single Residual Transformer가 다른 $V$개의 residual quantization layers의 토큰를 모델링하도록 학습
- $V$개의 개별 임베딩 레이어를 제외하고, Masked Transformer와 구조는 비슷하다.
학습 방법
- 학습할 layer $j\in[1,V]$를 무작위로 선택
- 선택된 layer의 이전 layer들의 모든 토큰$t^{0:j-1}$은 임베딩되고 합산되어 토큰 임베딩 입력으로 사용
- 토큰 임베딩, 텍스트 임베딩, $\text{RQ}$ layer ID $j$를 input으로 하는 Residual Transformer$~p_\phi$는 병렬로 $j$-$\text{th}$ layer의 토큰을 예측하도록 학습
Training Objective는 다음과 같다
$\mathcal{L}{{res}} = \sum\limits{j=1}^{V} \sum\limits_{i=1}^{n} -\log p_{\phi} \left( t^{j}{i} \mid t^{1:j-1}{i}, {c}, j \right)$
효율적인 학습을 위해 $j$-$\text{th}$ prediction layer와 $(j+1)$-$\text{th}$ 모션 토큰 임베딩 layer의 파라미터를 공유
We learn a single residual transformer to model the tokens from the other V residual quantization layers. The residual transformer has a similar architecture to the masked transformer (Sec. 3.2), except that it contains V separate embedding layers. During training, we randomly select a quantizer layer $j\in[1,V]$ to learn. All the tokens in the preceding layers $t^{0:j-1}$ are embedded and summed up as the token embedding input. Taking the token embedding, text embedding, and RQ layer indicator j as input, the residual transformer $p_\phi$ is trained to predict the j-th layer tokens in parallel. Overall, the training objective is:
$\mathcal{L}{{res}} = \sum\limits{j=1}^{V} \sum\limits_{i=1}^{n} -\log p_{\phi} \left( t^{j}{i} \mid t^{1:j-1}{i}, {c}, j \right)$
We also share the parameters of the $j$-$\text{th}$ prediction layer and $(j+1)$-$\text{th}$ motion token embedding layer for more
efficient learning.
Inference

추론은 세 단계로 구성되어있음.
- 모든 토큰이 마스킹 되어있는 empty sequence $t^0(0)$에서 시작해, base-layer 길이 $n$의 토큰 시퀀스 $t^0$를 $L$ iteration 안에 생성
- $l$-$\text{th}$ iteration 의 마스킹된 토큰 시퀀스 $t^0(l)$가 주어지면 M-Transformer는 마스킹된 위치에 대해 모션 토큰의 확률 분포를 예측
- 확률에 따라 모션 토큰 샘플링
- lowest $\lceil\gamma(\frac{l}{L})\cdot n\rceil$ confidence인 샘플된 토큰은 다시 마스킹, 다른 토큰들은 나머지 iteration동안 변동되지 않음
- 새로운 토큰 시퀀스 $t^0(l+1)$은 다음 iteration에서 토큰 시퀀스를 예측하는데 사용
- $l$이 $L$에 도달할 때 까지 반복
- 한번 base-layer 토큰이 완벽하게 생성된다면 R-Transformer는 나머지 quantization layer의 토큰 시퀀스를 점진적으로 예측
Once the baselayer tokens are completely generated, the R-Transformer progressively predicts the token sequence in the rest quantization layers. - 마지막으로, 모든 토큰은 디코딩 되고, RVQ-VAE 디코더를 통해 모션 시퀀스로 투영됨
Classifier Free Guidance
M-Transformer와 R-Transformer의 예측을 위해 Classifier-Free Guidance(CFG) 적용
학습 단계에서…
- 10% 확률로 조건 $c$를 비워$(c=\emptyset)$ unconditionally Transformer 학습
추론 단계에서…
- softmax 이전 최종 linear projection layer에서 CFG가 적용되며, 최종 logits$~\omega_g$는 conditional logits $\omega_c$를 unconditional logits $\omega_u$로 guidance scale $s$만큼 이동하여 계산됩니다.
$\omega_g=(1+s)\cdot\omega_c-s\cdot\omega_{u\cdot}$
Experiments
실험 평가는 두 가지 널리 사용되는 motion-language 벤치마크인 HumanML3D, KIT-ML에서 수행
HumanML3D
- AMASS 및 HumanAct12에서 14,616개의 모션 데이터셋 수집
- 각 모션당 3개의 텍스트 설명으로 구성, 총 44,970개의 설명
- 운동, 춤, 곡예 등 다양한 액션 포함
KIT-ML
- 3,911개의 모션
- 6,278개의 텍스트 설명
- 소규모 평가용 벤치마크 제공
두 모션 데이터셋에 대해 T2M 연구가 사용하던 포즈 표현 방식 채택
- 데이터 증강: 미러링 기법으로 다양성 증대 (좌우 미러링)
- Training(80%), Test(15%), Validation(5%) 비율로 분할
Evaulation Metrics
T2M에 사용된 평가 지표 또한 채택됨
- $Frechet Inception Distance~(FID)$
- 생성된 모션과 원본 모션의 분포 차이를 계산해 전반적인 모션 품질 평가
- 각 모션의 high-level feature의 분포 차이를 계산
- $R-Precision$ and $multimodal distance$
- input text와 생성된 모션 사이의 semantic alignment 측정
- $Multimodality$
- 같은 텍스트로 생성된 모션들의 다양성 평가
$Multimodality$가 중요하지만, $\mathbf{FID}$나 $\mathbf{RPrecision}$과 같은 주요 성능 지표와 함께 평가되는 보조 지표로의 역할을 강조
생성된 결과의 전반적인 퀄리티를 고려하지 않고 multimodality만 강조한다면, 어떤 입력에서도 무작위 출력을 생성하는 모델이 될 수 있음
Implementation Details
- 모델 구현
- PyTorch
- 모션 $\mathbf{residual~VQ-VAE}$
- 인코더와 디코더
- residual block 사용
- down scale factor 4
- 인코더와 디코더
- $\mathbf{RVQ}$
- 6개의 quantization layers
- 각 코드북에 512 512-차원 코드
- 양자화 dropout 비율 $q=0.2$
- Masked Transformer / Residual Transformer
- 6개의 transformer layers
- heads = 6, latent dimentions = 384
- 학습 설정
- Learning rate
- 2000회 반복 후 $\text{2e-4}$ 도달 ( 선형 warm-up schedule )
- Mini-Batch 크기
- $\text{RVQ-VAE}$: 512
- Transformers: HumanML3D 64, KIT-ML 32
- Learning rate
- 추론 설정
- CFG scale
- HumanML3D: M-Transformer 4, R-Transformer 5
- KIT-ML: M-Transformer 2, R-Transformer 5
- CFG scale
- $L$: 두 데이터 셋에서 10


